Time Series
Jack Tarricone, Mariana Webb, Tracy Shane
Here is the download link for the R script for this lecture: time series script
Import Packages
library(rnoaa) # package for downloading NOAA, NCDC, and GHCN data
library(forecast) # time series forecasting
library(tseries) # useful functions and tests
library(tsutils) # more tests
library(tidyverse)
library(lubridate) # date management
library(ggplot2)
library(dataRetrieval) # packaage for downloading USGS stream flow data
library(dplyr) # for data formatting
library(trend) # for MK test and sen's slope
library(zyp) # y-intercept calc for sen's slope
library(changepoint)Introduction
What is a time series?
A time series is a sequence of repeat measurements that are obtained over time. Analysis of time series data allows us to better understand how things are changing with respect to time, ranging from milliseconds to eons.
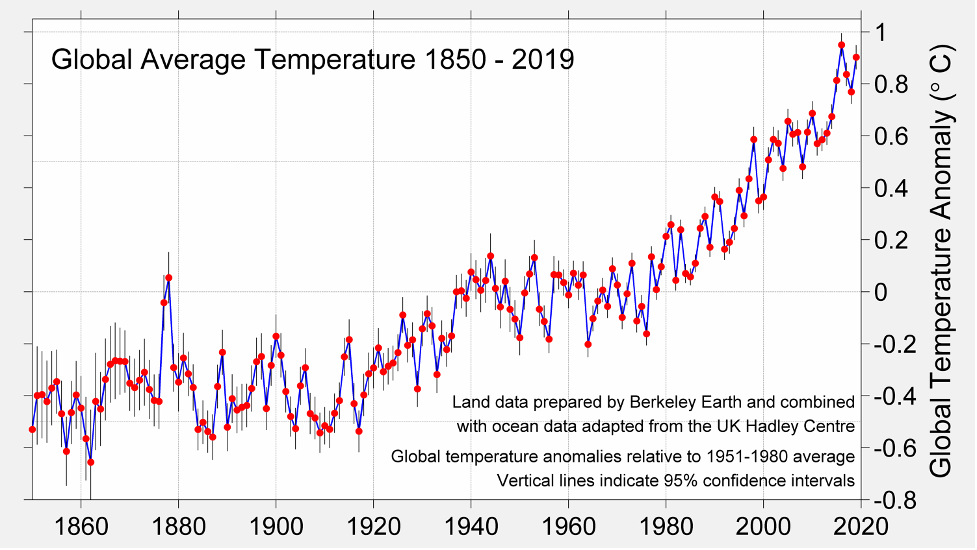
This plot shows the global annual average temperature anomaly from 1860 to 2020.
Why is time series analysis important?
Data collected near to the time that other data is collected is often correlated. We want to look at trends in data or for change points due to treatment or management. It is helpful for developing forecasting models.
What do we need to do time series analysis?
- A sequence of a minimum of 30 observations (but some say 60 observations)
- A sequence that spans enough cycles of the data to model them accurately
- A sequence that, if seasonal, contains enough seasons to model them accurately
- Data collected from a representative sample of the population
Time series terminology
Discrete vs. Continuous: a time series is discrete if measurements are taken at regularly-spaced intervals in time, continuous if measurements are taken continuously.
Stationarity vs. Non-Stationarity: a time series is stationary if the mean and covariance of the data set stays constant over time. 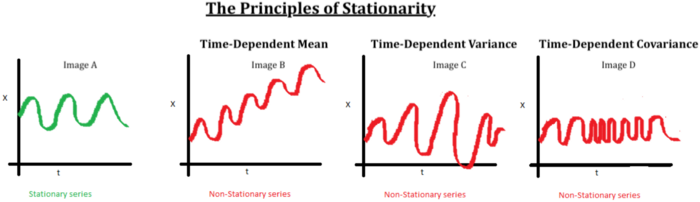
Lag: shifting a time series i periods back.
Stochastic Processes: a process defined by random variables, defined on the same probability space.
Forecasting: making predictions about future time series behavior based on a model fit to the historic data.
Model
Time Series is represented as Y-1, Y0, [Y1, Y2, ….., YN], YN+1, ….
The observed time series in [Y1, Y2, ….., YN] is the probability sample of the complete time series and is given weights as specified by the statistical model.
Full Model:
Yt = N(at) + X(It)
Where: at is the t th observation of a strictly exogenous innovation time series with a white noise property: at ~ iid Normal(0, σ2a) and, It is the tth observation of a causal time series, usually in the format of a binary variable of presence or absence of a treatment, or it can be a purely stochastic time series.
Solved for at with the white noise properties, we will often use the solved model for statistical tests:
at = N-1[Yt- X(It)]
Experiemental Designs
Three main types of time-series experiments:
- Descriptive
- Observation of trends and cycles, interpretation of time series components
- Precedes hypothesis testing
- Unable to rule out alternative hypotheses
- Often uninterpretable in terms of causation
- Correlational
- Infer a causal relationship between two series from their covariance
- Reliant on strong theoretical foundation, otherwise invalid
- Usually limited to small segments of economics and psychology
- Experimental or Quasi-experimental
- Interrupted Time Series Designs: tests latent causal effects due temporally discrete intervention or treatment. Divides the time series in the pre and post intervention segments to test hypotheses.
Getting Started with Time Series Data
Importing Time Series Data
For this example, we are using temperature and precipitation data from NOAA’s GHCN. We use the rnoaa package to download monthly data for the Reno Airport station for 80 years between 1940 and 2020.
Get an NCEL authentication key from https://www.ncdc.noaa.gov//cdo-web/token.\
“PRCP” = Total Monthly Precipitation. Given in millimeters.
“EMXP” = Extreme Maximum Precipitation. Given in millimeters.
“TMIN” = Monthly Minimum Temperature. Average of daily minimum temperature given in Celsius.
“TMAX” = Monthly Maximum Temperature. Average of daily maximum temperature given in Celsius.
For more information about the GHCN monthly data set: https://www.ncei.noaa.gov/pub/data/metadata/documents/GSOMReadme.txt
stationID <- 'USW00023185' # Reno airport (1937-03-01 to present)
dataset <- 'GSOM' # Global Summary of the Month
climateVars <- c('TMIN', 'TMAX', 'PRCP', 'EMXP') # select climate variables to download
startDate <- as.Date('1940-01-01')
endDate <- as.Date('2020-12-31')
GHCN <- getGHCN(dataset, stationID, climateVars, startDate, endDate) # Call to download data using a wrapper functionA great first step in time series analysis is to plot all the data to see what we’re working with.
ggplot(GHCN, aes(as.Date(date), value, color = datatype)) +
geom_point() +
facet_wrap(~datatype, scales = 'free') +
scale_x_date(date_breaks = '20 years', date_labels = "%Y") +
labs(x = "", y = "")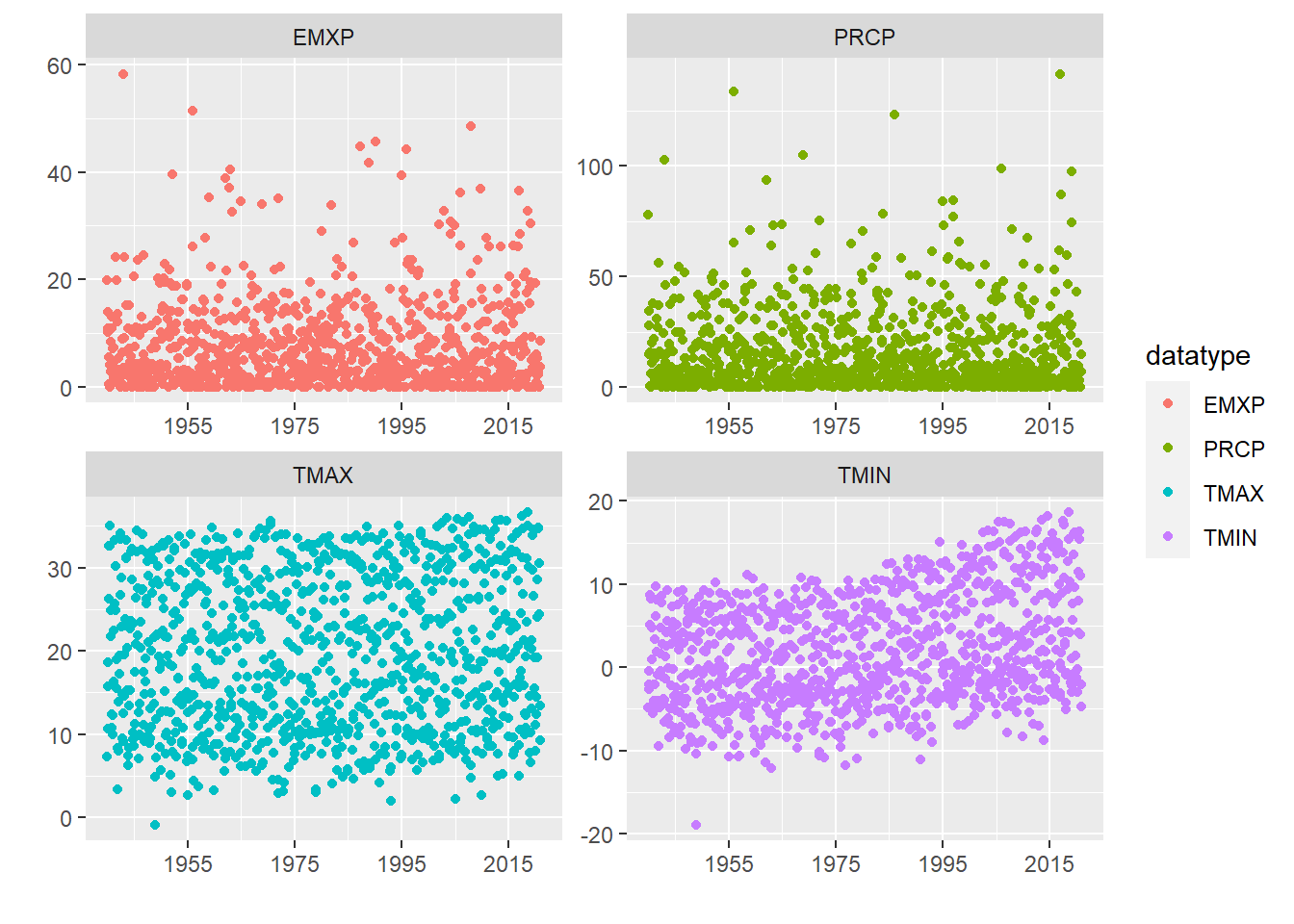
R Time Series Objects
The ts object is part of base r but other packages like zoo and xts provide additional ways to create and manage time series objects. A ts object is a very simple, taking a vector or matrix of the time series data values, a start and/or end time for the period of observations, and a frequency which indicates the number of observations per unit time. Let’s convert our minimum temperature time series into a ts object.
tmin <- GHCN %>%
filter(datatype == 'TMIN') %>% # select only 'TMIN' data from downloaded data frame
select(value) # select only the data value column, we don't need the stationID, date, or datatype columns
# the ts() function converts to an r time series object
# input data is a vector or matrix of data
tmin.ts <- ts(tmin, frequency = 12, start = c(1940, 1))
head(tmin.ts, n = 60) # look at the first 5 years of data## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
## 1940 -4.85 -2.09 -2.69 -0.48 5.11 8.67 8.26 8.51 4.74 0.91 -5.25 -5.55
## 1941 -4.05 -2.09 -4.63 -2.00 3.35 6.16 9.75 8.08 1.92 -0.88 -4.06 -4.43
## 1942 -9.41 -4.72 -4.85 -0.45 1.68 4.72 8.62 7.74 2.85 -1.15 -3.74 -4.35
## 1943 -6.57 -3.96 -1.42 1.29 2.57 4.22 9.34 5.54 4.33 -0.10 -6.11 -8.38
## 1944 -6.75 -4.96 -4.98 -2.22 2.86 4.62 7.33 5.46 3.92 -0.18 -3.40 -7.81plot.ts(tmin.ts, ylab = "Min. Temp. (C)") # plot the time series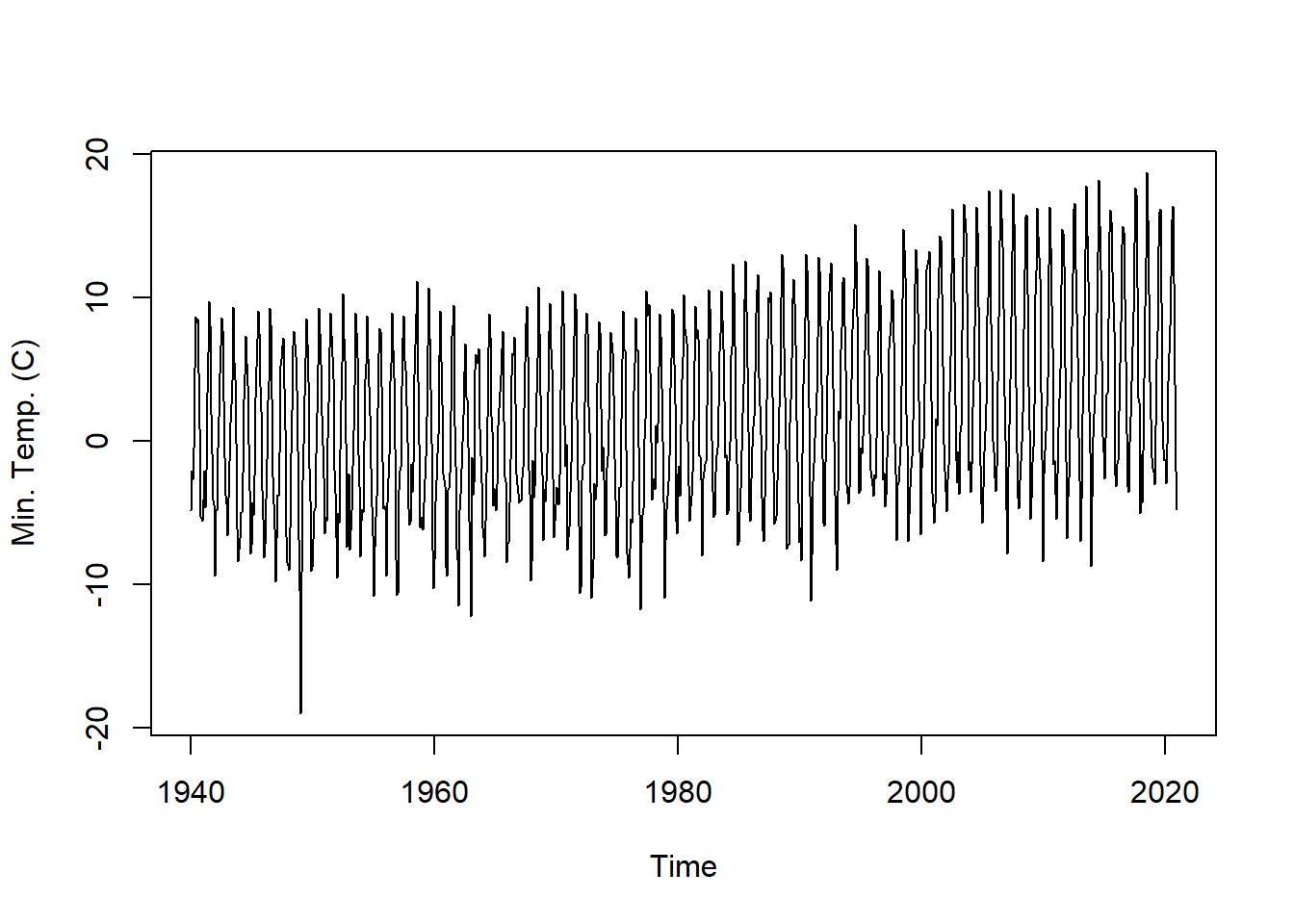
# explore the time series object and other information it contains
start(tmin.ts)## [1] 1940 1end(tmin.ts)## [1] 2020 12frequency(tmin.ts)## [1] 12Time Series Decomposition
Decomposition is a way to parse out the different contributing signals of a time series. Frequently, decomposition is used to remove seasonality, making the long-term trend clearer. Decomposition can also be used to detrend a time series. The random signal in a time series can be used to identify outliers and anomalous data.
Before detrending, we need to determine if we’re working with an additive or multiplicative time series.
Additive time series don’t change in magnitude over time.
Multiplicative time series see an increase in seasonal magnitude over time.
Is the Reno Airport minimum temperature time series additive or multiplicative? The mseastest() function in the tsutils function provides a quick test for seasonality.
plot.ts(tmin.ts, ylab = "Min. Temp. (C)") # plot the time series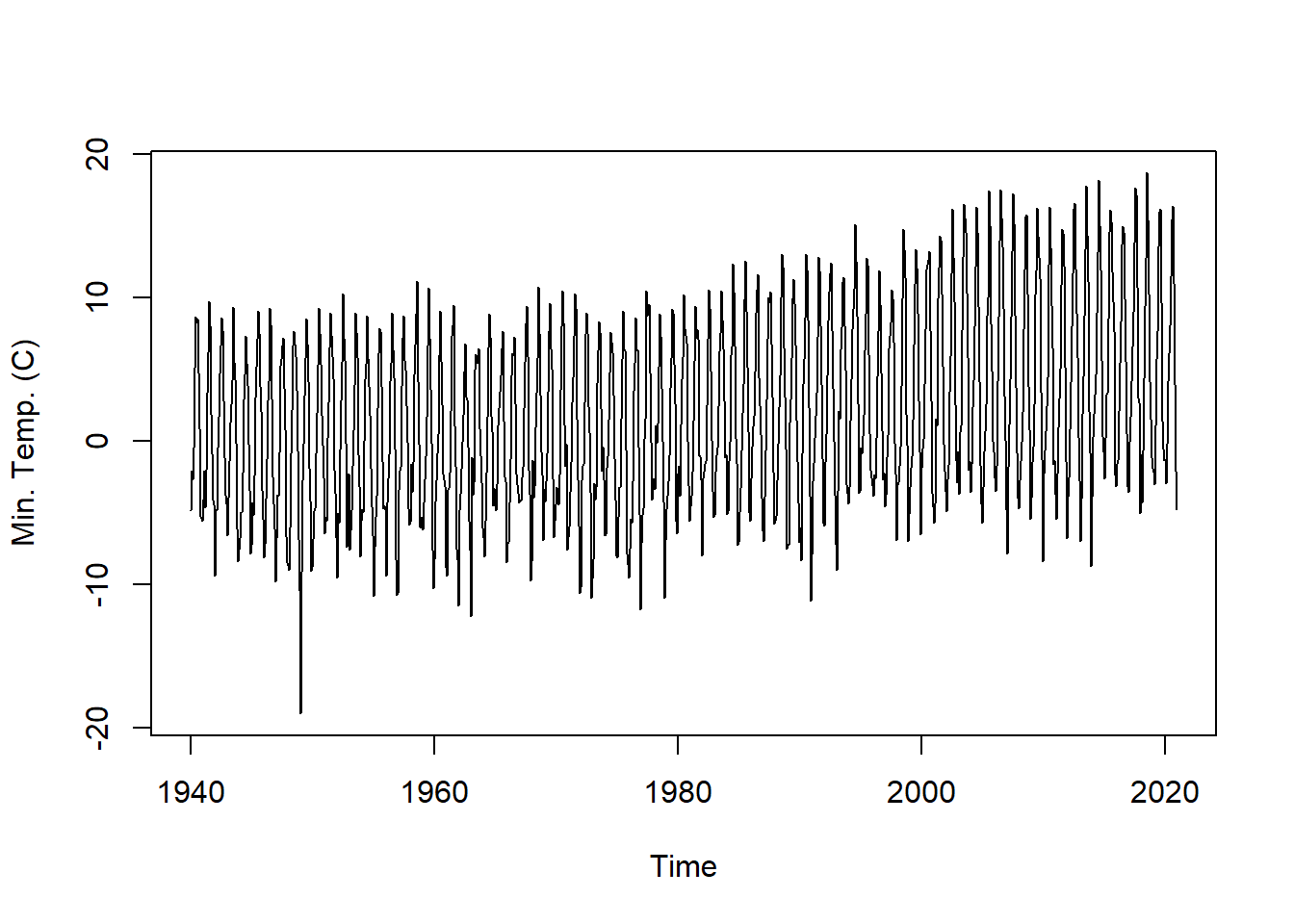
tsutils::mseastest(tmin.ts, outplot = 1)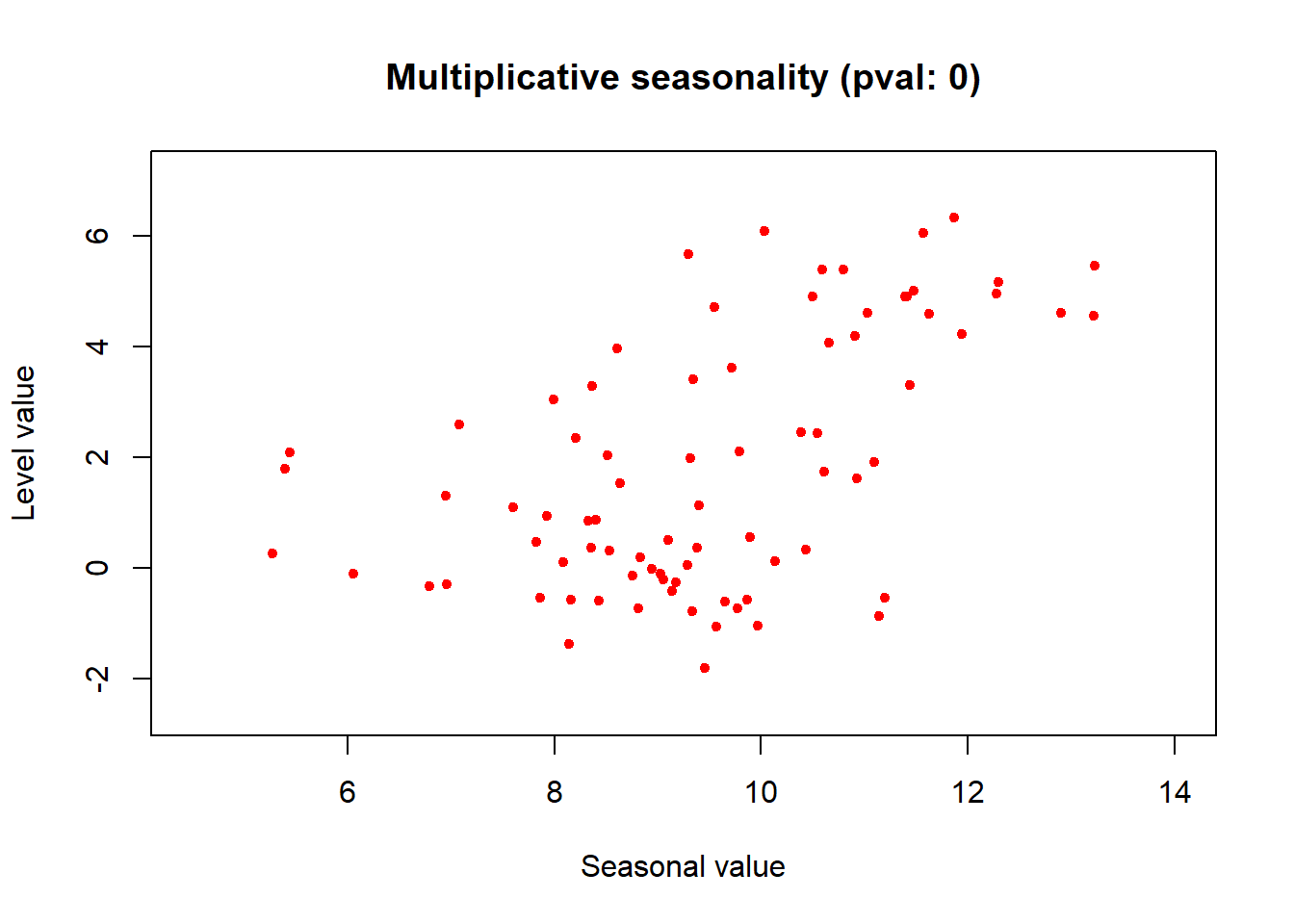
## $is.multiplicative
## [1] TRUE
##
## $statistic
## [1] 0.5326024
##
## $pvalue
## [1] 1.544398e-07Looks like this time series is multiplicative! Let’s decompose the plot multiplicatively.
tminDecompose <- decompose(tmin.ts, type = "multi")
plot(tminDecompose)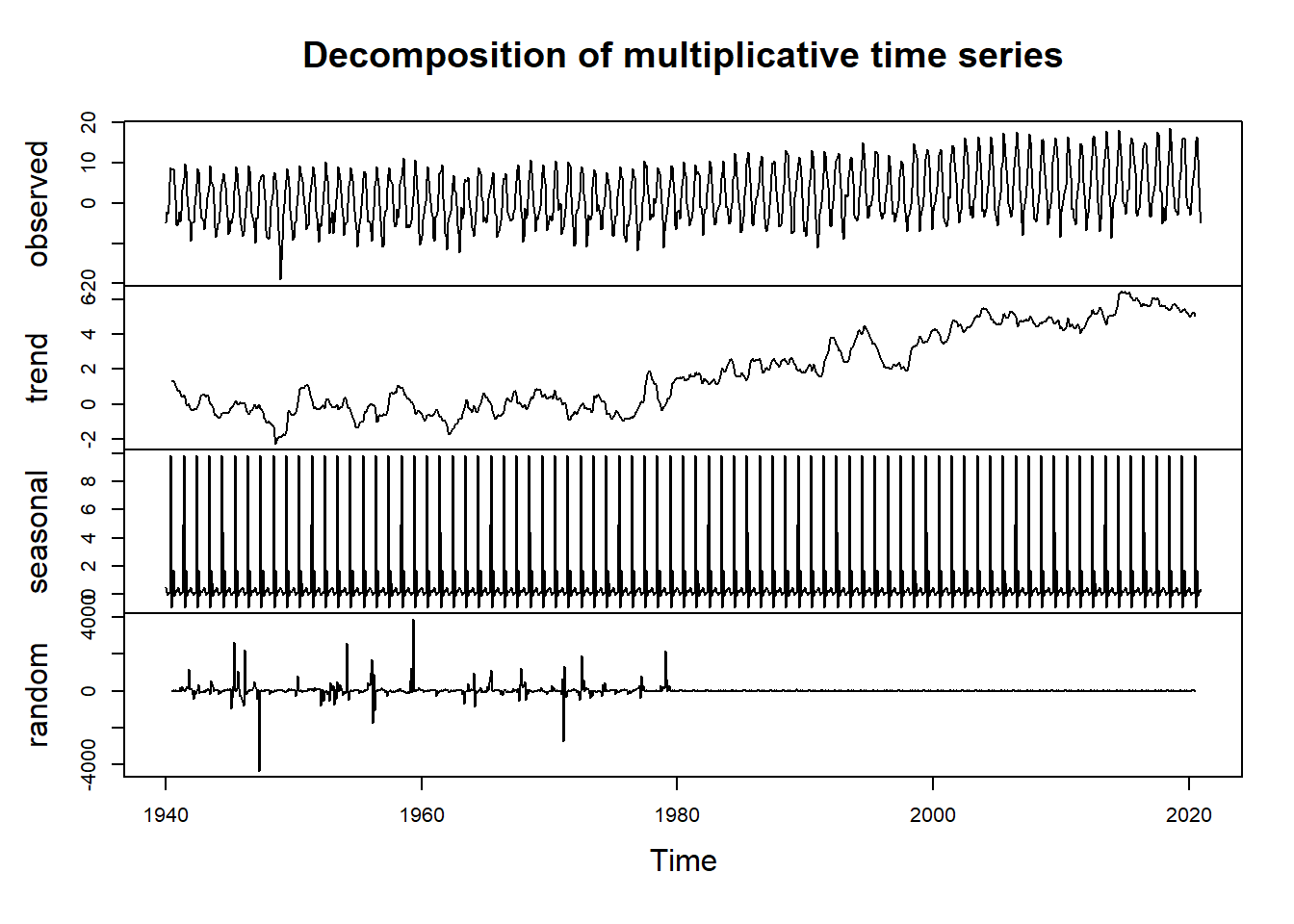
The observed plot represents the original observed values for monthly minimum temperature at the Reno Airport.
The trend plot shows the underlying trend of the data. We can see here a positive trend in the data, suggesting increasing temperatures over the course of the 80 year data period.
The seasonal plot shows patterns that repeat at a regular interval. In this case, the temperature data shows strong seasonailty with lower values in the winter months and higher values in the summer months.
The random plot shows the residuals of the time series after the trend and seasonal parts are removed.
Time Series Adjustments
If the seasonality of the temperature is not of interest, we can simply subtract the seasonality from the original time series to get a seasonally-adjusted time series.
tminSeasonAdj <- tmin.ts - tminDecompose$seasonal
plot.ts(tminSeasonAdj,
main = "Seasonally-Adjusted Minimum Monthly Temperature",
ylab = "Min. Temp. (C)")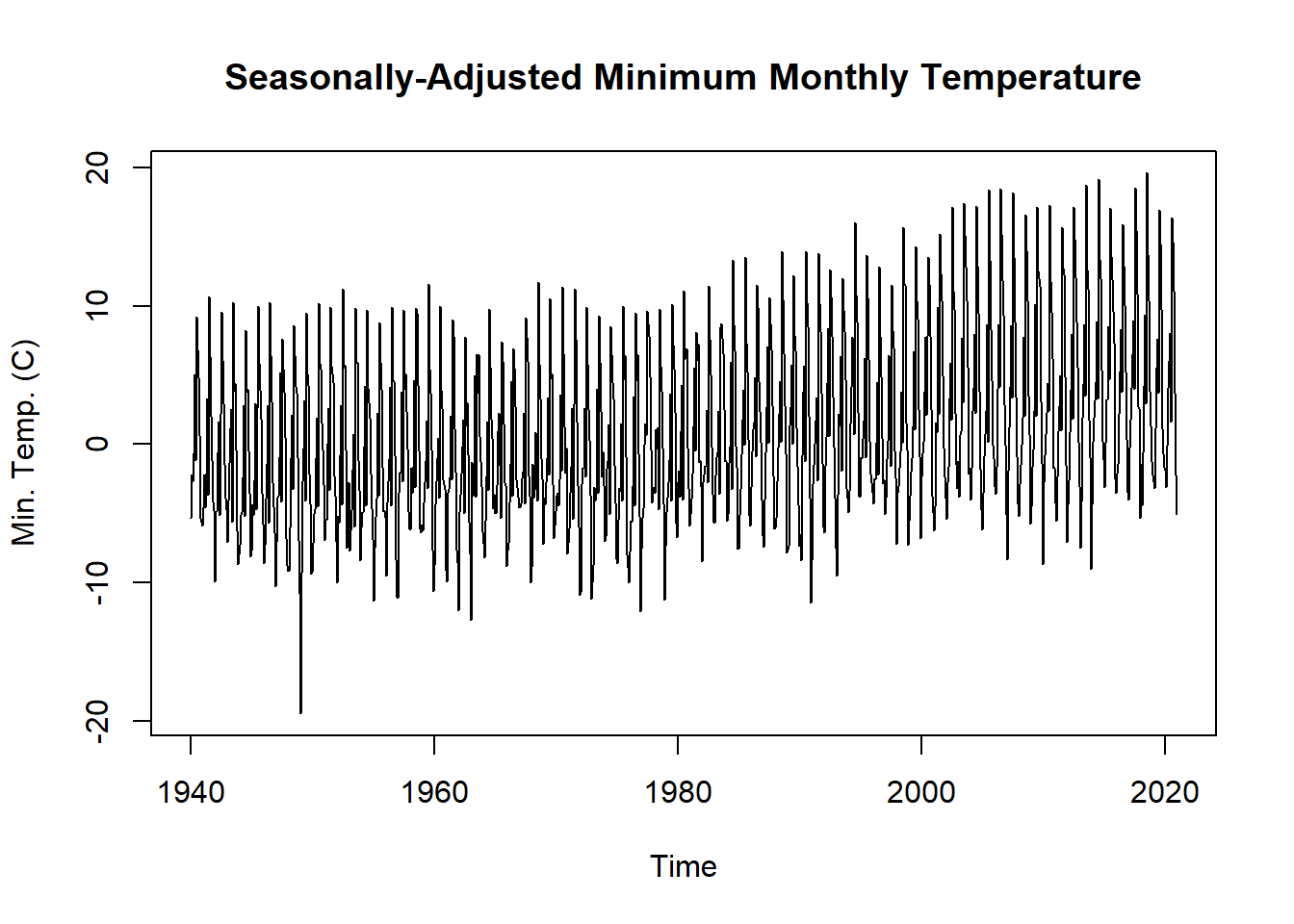
In other cases, such as running a regression on two time series, we might want to remove the trend from a non-stationary time series. To remove the trend from the dataset, we can simply subtract the trend from the original time series.
tminTrendAdj <- tmin.ts - tminDecompose$trend
plot.ts(tminTrendAdj,
main = "Detrended Minimum Monthly Temperature",
ylab = "Min. Temp. (C)")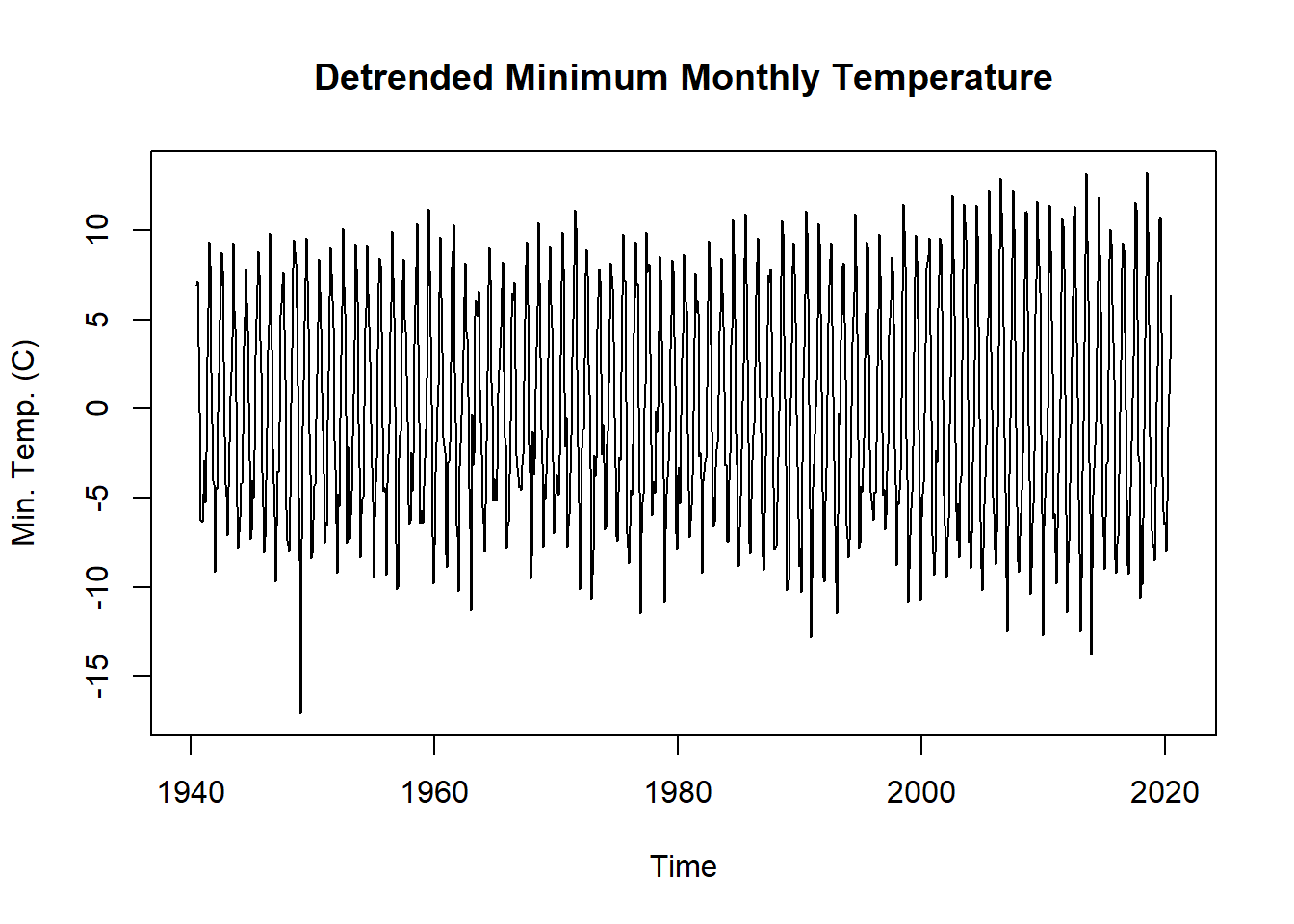
Time Series Forecasting and Forecasting Objects
Another object type in r relevant to time series is the forecast object. A forecast object contains prediction intervals, fitted values, residuals, information about the method and data used to forecast. There are two types of forecast models. In the first, a function directly produces a forecast object. In the second, we first fit a model to the data and only then use a function to forecast from that model.
Here, we will do a simple forecast using a Seasonal and Trend Decompostion using Loess Forecasting Model (STLF) and the naive method, which uses the most recent values of the time series to project the time series into the future. Other possible methods include ETS, ARIMA, and Random Walk Drift.
tminForecast <- forecast::stlf(tmin.ts, method = "naive")
plot(tminForecast,
main = "Minimum Monthly Temperature with Forecasting through 2022",
ylab = "Min. Temp. (C)")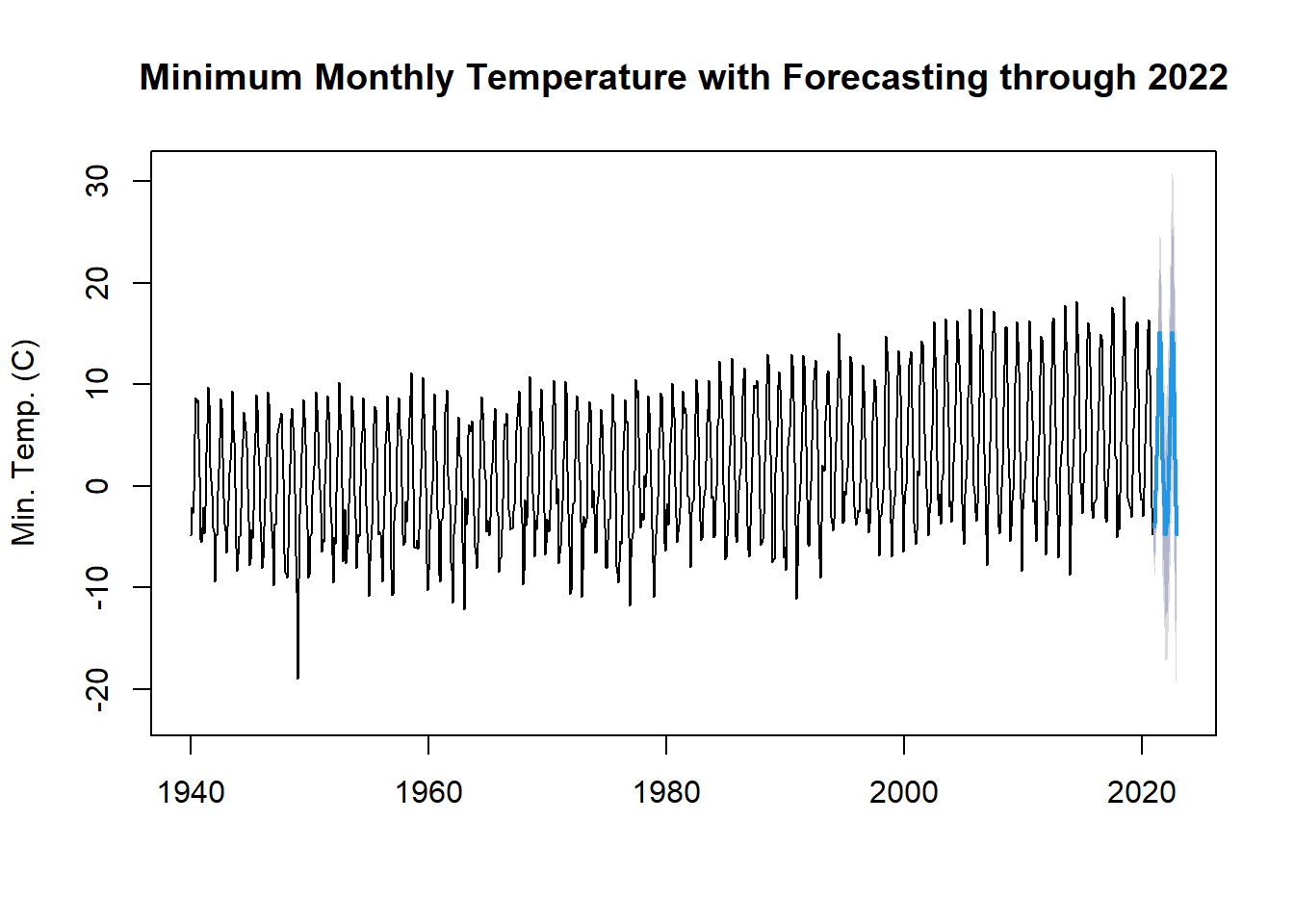
Hydroclimatic Trend Analysis
For this section, we’ll work through a trend analysis using USGS streamflow data. We’ll start by downloading the data directly into R, formatting the date information, and then calculating hydrologic statistics which will be tested for significant trends. This type of analysis is common in hydrologic and climatologic science.
This map shows the location on the gauge, with the drainage area shaded in grey.
This gauge was selected because there are no significant diversions or damns in the drainage basin above. Therefore, any trends we may find should be related to changes in the hydroclimatology of the area.
# identifying parameters for data download
siteNumber <- "11413000" # USGS gauge number
parameterCd <- "00060" # mean daily discharge in cfs
startDate <- "1940-10-01" # starting date bc missing few years in the 30's
endDate <- "2021-11-01" # date todayWe’ll use the dataRetrevial package to download the daily stream gauge data into R. To select a different gauge, simply look up the site number and download.
# download data using readNWISdv function
yuba_raw <- dataRetrieval::readNWISdv(siteNumber, parameterCd, startDate, endDate)
head(yuba_raw) # check## agency_cd site_no Date X_00060_00003 X_00060_00003_cd
## 1 USGS 11413000 1940-10-01 148 A
## 2 USGS 11413000 1940-10-02 148 A
## 3 USGS 11413000 1940-10-03 160 A
## 4 USGS 11413000 1940-10-04 157 A
## 5 USGS 11413000 1940-10-05 152 A
## 6 USGS 11413000 1940-10-06 147 Acolnames(yuba_raw)[4] <-"discharge_cfs" # rename column 4
yuba_raw <-yuba_raw[,-5] # delete unused colDate Formatting
When conducting time series analysis in R, it’s important to have your date information formatted so that you find it easy to work with. We will create additional columns using lubridate for time information to help filter and group the data for further analysis.
class(yuba_raw$Date) # check it's actually a data not a character string## [1] "Date"yuba_raw$year <-lubridate::year(yuba_raw$Date) # add year col
yuba_raw$month <-lubridate::month(yuba_raw$Date) # add month col
yuba_raw$day <-lubridate::day(yuba_raw$Date) # add day of month col
yuba_raw$doy <-lubridate::yday(yuba_raw$Date) # add day of year colA water year (WY) is a standard time metric for evaluating streamflow and snowpack data in hydrology. It starts on October 1st and ends on September 30th of the following year. The water year is defined by year in which the September 30th date occurs. WY 2022 began on October 1st of last month!
yuba_raw <-dataRetrieval::addWaterYear(yuba_raw)
head(yuba_raw) # check## agency_cd site_no Date waterYear discharge_cfs year month day doy
## 1 USGS 11413000 1940-10-01 1941 148 1940 10 1 275
## 2 USGS 11413000 1940-10-02 1941 148 1940 10 2 276
## 3 USGS 11413000 1940-10-03 1941 160 1940 10 3 277
## 4 USGS 11413000 1940-10-04 1941 157 1940 10 4 278
## 5 USGS 11413000 1940-10-05 1941 152 1940 10 5 279
## 6 USGS 11413000 1940-10-06 1941 147 1940 10 6 280Now using dplyr we’ll group by water year, and create a column that is a sequence or count of days begining on October 1st. This will create a metric for day of water year (dowy), account for leap and non-leap years correctly.
yuba <- as.data.frame(dplyr::group_by(yuba_raw,waterYear)
%>% mutate(dowy = seq(1:n())))
head(yuba)## agency_cd site_no Date waterYear discharge_cfs year month day doy dowy
## 1 USGS 11413000 1940-10-01 1941 148 1940 10 1 275 1
## 2 USGS 11413000 1940-10-02 1941 148 1940 10 2 276 2
## 3 USGS 11413000 1940-10-03 1941 160 1940 10 3 277 3
## 4 USGS 11413000 1940-10-04 1941 157 1940 10 4 278 4
## 5 USGS 11413000 1940-10-05 1941 152 1940 10 5 279 5
## 6 USGS 11413000 1940-10-06 1941 147 1940 10 6 280 6tail(yuba)## agency_cd site_no Date waterYear discharge_cfs year month day doy
## 29612 USGS 11413000 2021-10-27 2022 640 2021 10 27 300
## 29613 USGS 11413000 2021-10-28 2022 627 2021 10 28 301
## 29614 USGS 11413000 2021-10-29 2022 522 2021 10 29 302
## 29615 USGS 11413000 2021-10-30 2022 461 2021 10 30 303
## 29616 USGS 11413000 2021-10-31 2022 441 2021 10 31 304
## 29617 USGS 11413000 2021-11-01 2022 397 2021 11 1 305
## dowy
## 29612 27
## 29613 28
## 29614 29
## 29615 30
## 29616 31
## 29617 32Let’s plot the full daily time series using ggplot2 Dr. Shoemaker’s favorite plotting package!
# set theme for plot, changes background to white
ggplot2::theme_set(theme_light(base_size =11))
# plot
ggplot(yuba, aes(y = discharge_cfs, x = Date))+
geom_line(size = .3) + # change line width
labs(title="Yuba near Goodyears Bar,CA Discharge",
y="Discharge (cfs)", x="Date")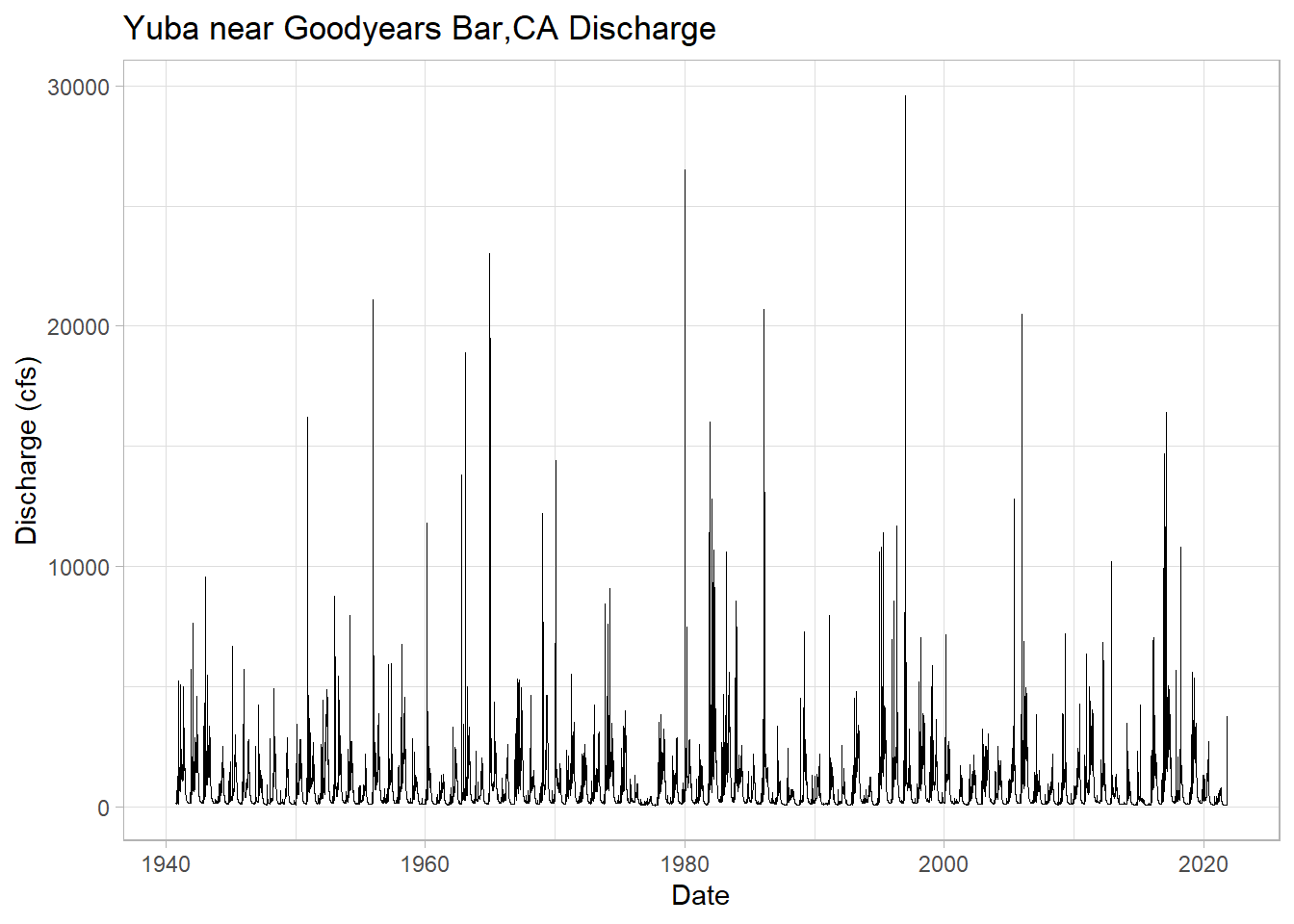
Plotting just WY 2021 with the added extra month, notice the spike from the recent AR event!
# filter the date down to the 2021 + 1 month water year and plot
yuba_wy2021 <-dplyr::filter(yuba, Date >= as.Date("2020-10-01") & Date <= as.Date("2021-11-01"))
# plot wy 2021
ggplot(yuba_wy2021, aes(y = discharge_cfs, x = Date))+
geom_line(size = .7, col = "darkblue") + # change width, set color
labs(title="Yuba near Goodyears Bar,CA Discharge WY 2021",
y="Discharge (cfs)", x="Date")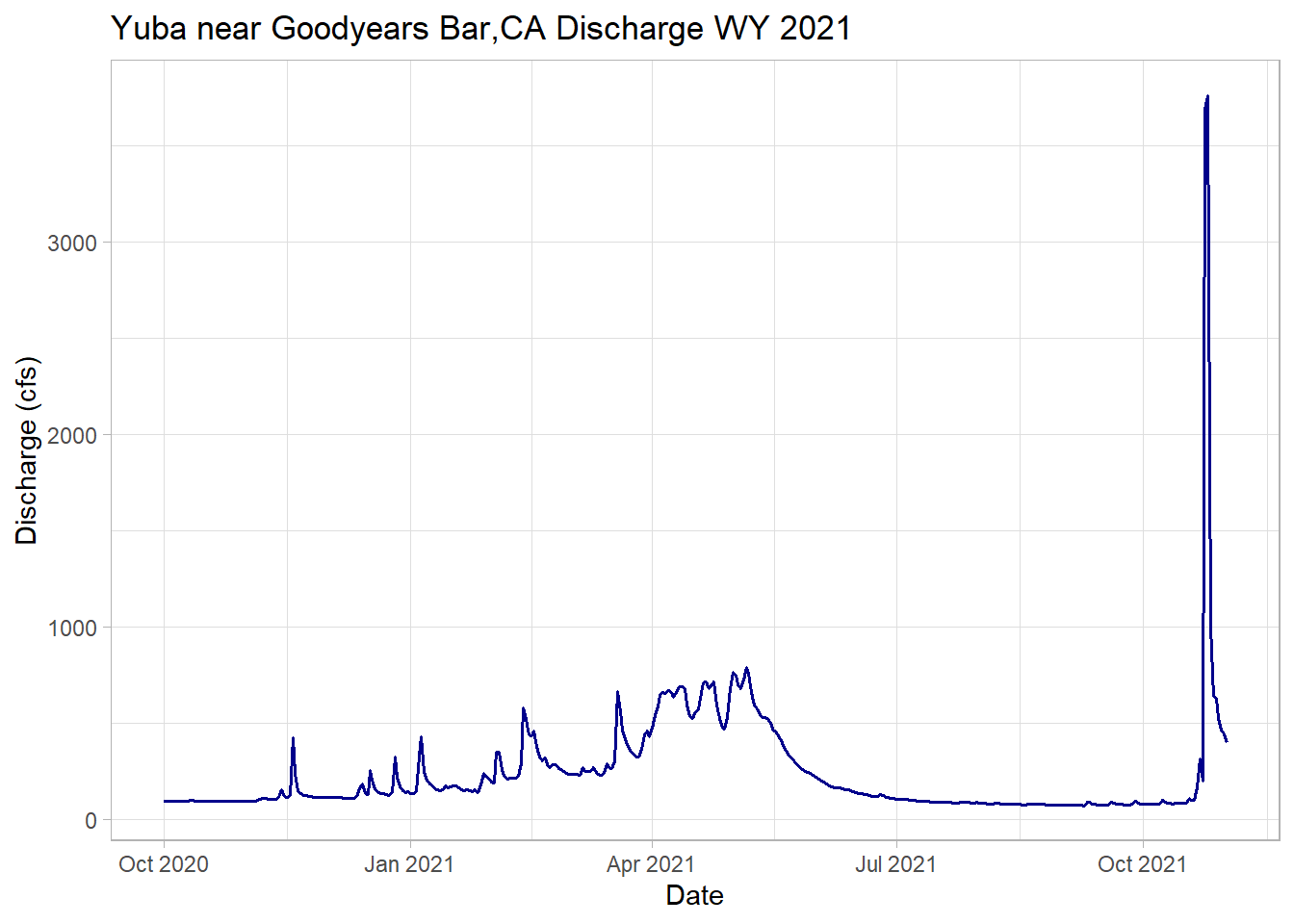
Streamflow Metrics
In the Sierra Nevada, the vast majority of the water flows from the mountains during the spring snowmelt season. Water managers and scientists must predict the timing and magnitude of peak streamflow to allocate the resource properly for a range of different purposes, including ecological benefit.
# create a dataframe of maximum daily discharge per year
wy_max <-as.data.frame(yuba %>%
group_by(waterYear) %>%
filter(discharge_cfs == max(discharge_cfs, na.rm=TRUE)))
head(wy_max) ## agency_cd site_no Date waterYear discharge_cfs year month day doy dowy
## 1 USGS 11413000 1940-12-27 1941 5240 1940 12 27 362 88
## 2 USGS 11413000 1942-01-27 1942 7640 1942 1 27 27 119
## 3 USGS 11413000 1943-01-21 1943 9580 1943 1 21 21 113
## 4 USGS 11413000 1944-05-08 1944 2510 1944 5 8 129 221
## 5 USGS 11413000 1945-02-02 1945 6670 1945 2 2 33 125
## 6 USGS 11413000 1945-12-29 1946 5730 1945 12 29 363 90# max day of water year
ggplot(wy_max, aes(y = dowy, x = Date)) +
geom_point(col = "goldenrod")+
geom_smooth(method = "lm", se = FALSE)+ # add lm trend line
labs(title="Yuba Max Annual Discharge DOWY",
y="Day of Water Year", x="Date")## `geom_smooth()` using formula 'y ~ x'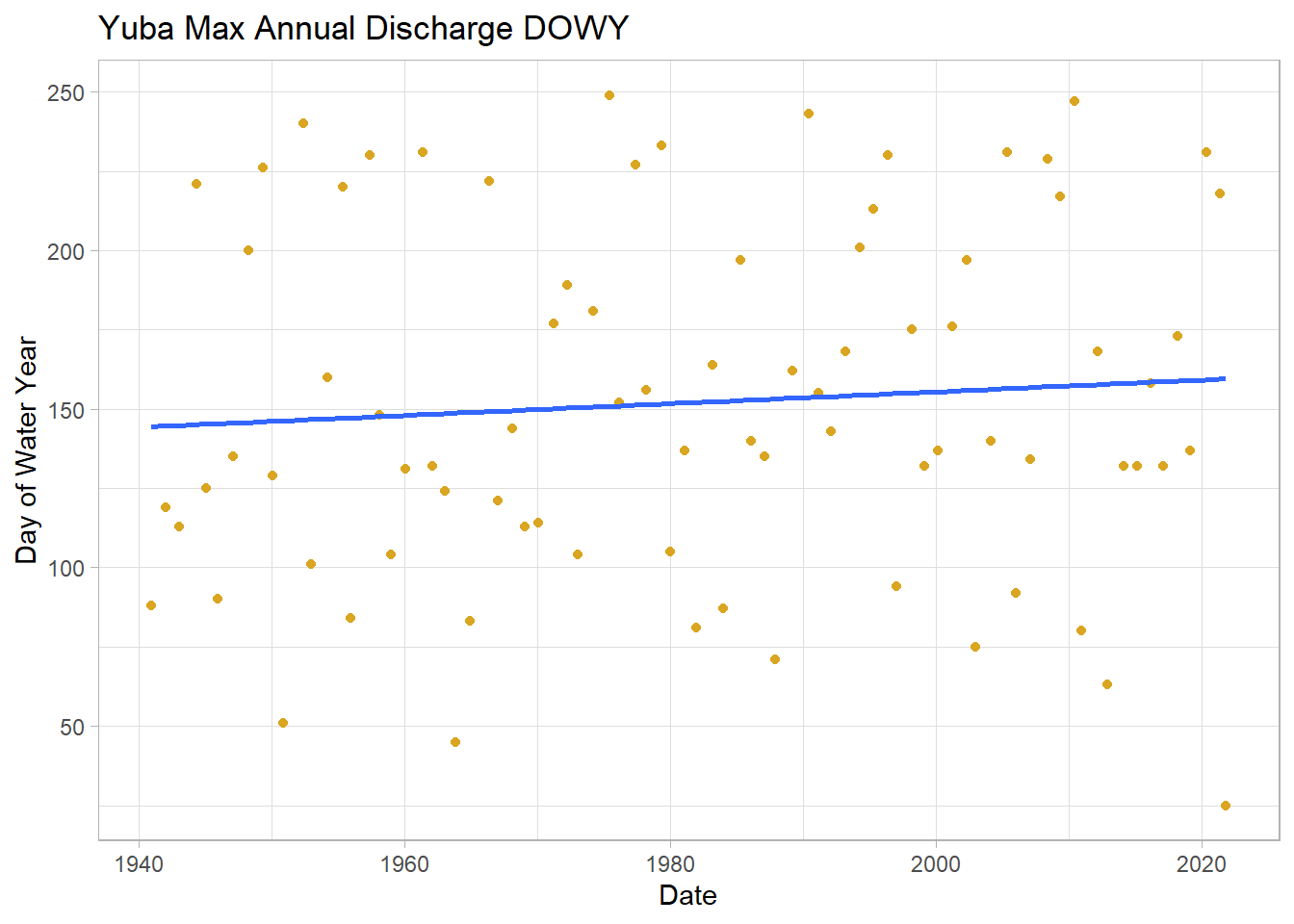
# max discharge cfs
ggplot(wy_max, aes(y = discharge_cfs, x = Date)) +
geom_point()+
geom_smooth(method = "lm", se = FALSE)+ # add lm trend line
labs(title="Yuba Max Annual Discharge DOWY Discharge",
y="Discharge (cfs)", x="Date")## `geom_smooth()` using formula 'y ~ x'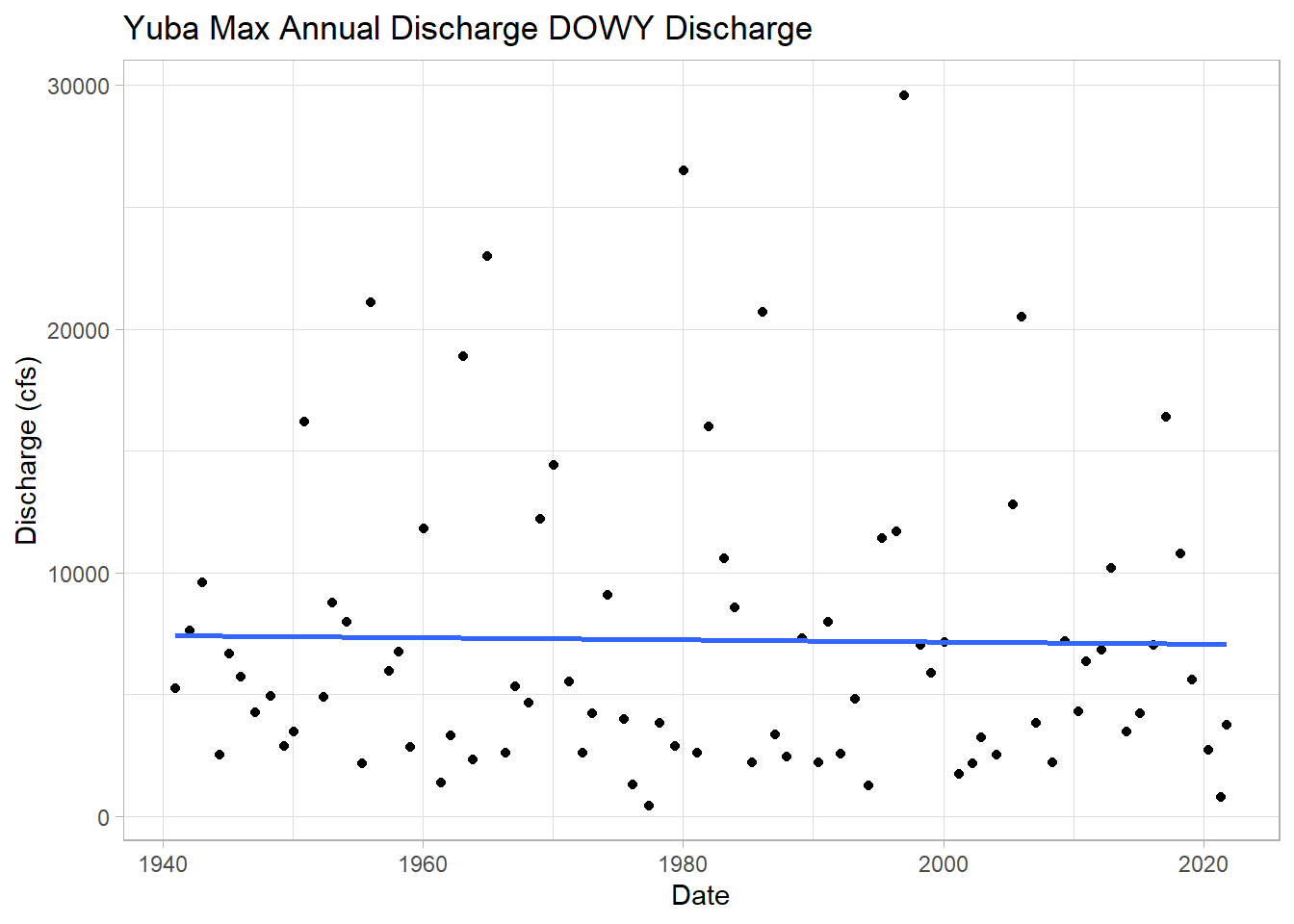
A bit tangential, but let’s calculate the maximum observed flow for the whole time series.
max <-dplyr::filter(yuba, discharge_cfs == max(discharge_cfs, na.rm=TRUE))
print(max)## agency_cd site_no Date waterYear discharge_cfs year month day doy dowy
## 1 USGS 11413000 1997-01-02 1997 29600 1997 1 2 2 94This was a massive rain-on-snow AR event that caused flows much larger than last month! More information here
Calculating the Onset of Spring Flows
Stewart et al. (2004) showed that the onset or time of spring stream flow in the Sierra is changing. Using the newly formatted data with the additional date information, we can to create a function that calculates date of spring flow onset in DOWY. I won’t go into detail of how, and am not 100% confident it’s correct, but let’s assume it is for the purposes of this exercise.
melt_onset_dowy <-function(df){
# crop days until until spring and early summer
wy_spring <-filter(df, dowy > 100 & dowy < 250) # crop days until until spring and early summer
mean_spring <-mean(wy_spring$discharge_cfs) # find meann discharge of spring date
above_mean_days <-wy_spring$dowy[which(wy_spring$discharge_cfs > mean_spring)] # find dates which discharge > mean
diff_vect <-diff(above_mean_days)
results <-rle(diff_vect)
meets <-as.numeric(min(which(results$lengths == max(results$lengths))))
values_to_cut <-results$lengths[1:(meets-1)]
#sum the lengths
index_values_until_start <-as.numeric(sum(values_to_cut))
#subtract that many values off to get your SDD
onset_dowy <-as.integer(min(above_mean_days[-c(1:index_values_until_start)]))
return(onset_dowy)
}Now we can apply this function to each water year and create a dataframe of water year’s and date of spring flow onset
# create sequence of available years
years <-as.matrix(seq(min(yuba$waterYear),2021,1))
# create an empty matrix to read the data into
loop_mat <-matrix(nrow = length(years))
# filter data to stop at WY 2021
yuba_loop <-dplyr::filter(yuba, Date >= as.Date("1940-10-01") & Date <= as.Date("2021-09-30"))
tail(yuba_loop)## agency_cd site_no Date waterYear discharge_cfs year month day doy
## 29580 USGS 11413000 2021-09-25 2021 74.5 2021 9 25 268
## 29581 USGS 11413000 2021-09-26 2021 74.2 2021 9 26 269
## 29582 USGS 11413000 2021-09-27 2021 75.6 2021 9 27 270
## 29583 USGS 11413000 2021-09-28 2021 94.2 2021 9 28 271
## 29584 USGS 11413000 2021-09-29 2021 83.0 2021 9 29 272
## 29585 USGS 11413000 2021-09-30 2021 80.1 2021 9 30 273
## dowy
## 29580 360
## 29581 361
## 29582 362
## 29583 363
## 29584 364
## 29585 365# loop the function for calculating melt onset through all the way years
for (i in 1:length(years)){
yearly_df <-subset(yuba_loop, waterYear == years[i]) # sequence through years to create yearly df
loop_mat[i] <-melt_onset_dowy(yearly_df) # apply function and sequentially save in empty matrix
}
# bind years vector and new melt onset dates
melt_onset_df <-as.data.frame(cbind(years, loop_mat))
colnames(melt_onset_df)[1] <-"waterYear"
colnames(melt_onset_df)[2] <-"spring_flow_dowy"
tail(melt_onset_df) # check## waterYear spring_flow_dowy
## 76 2016 157
## 77 2017 215
## 78 2018 172
## 79 2019 184
## 80 2020 188
## 81 2021 180Quick test plot of the spring flow onset metric we just created, with a linear model laid on top.
# plot the new data and add a "trend line", just visually
# seems to trend towards early flow onset
ggplot(melt_onset_df, aes(y = spring_flow_dowy, x = waterYear)) +
geom_point(col = "red")+
geom_smooth(method = "lm", se = FALSE) +
labs(title="Yuba Spring Flow Onset Date",
y="Day of Water year", x="Water Year")## `geom_smooth()` using formula 'y ~ x'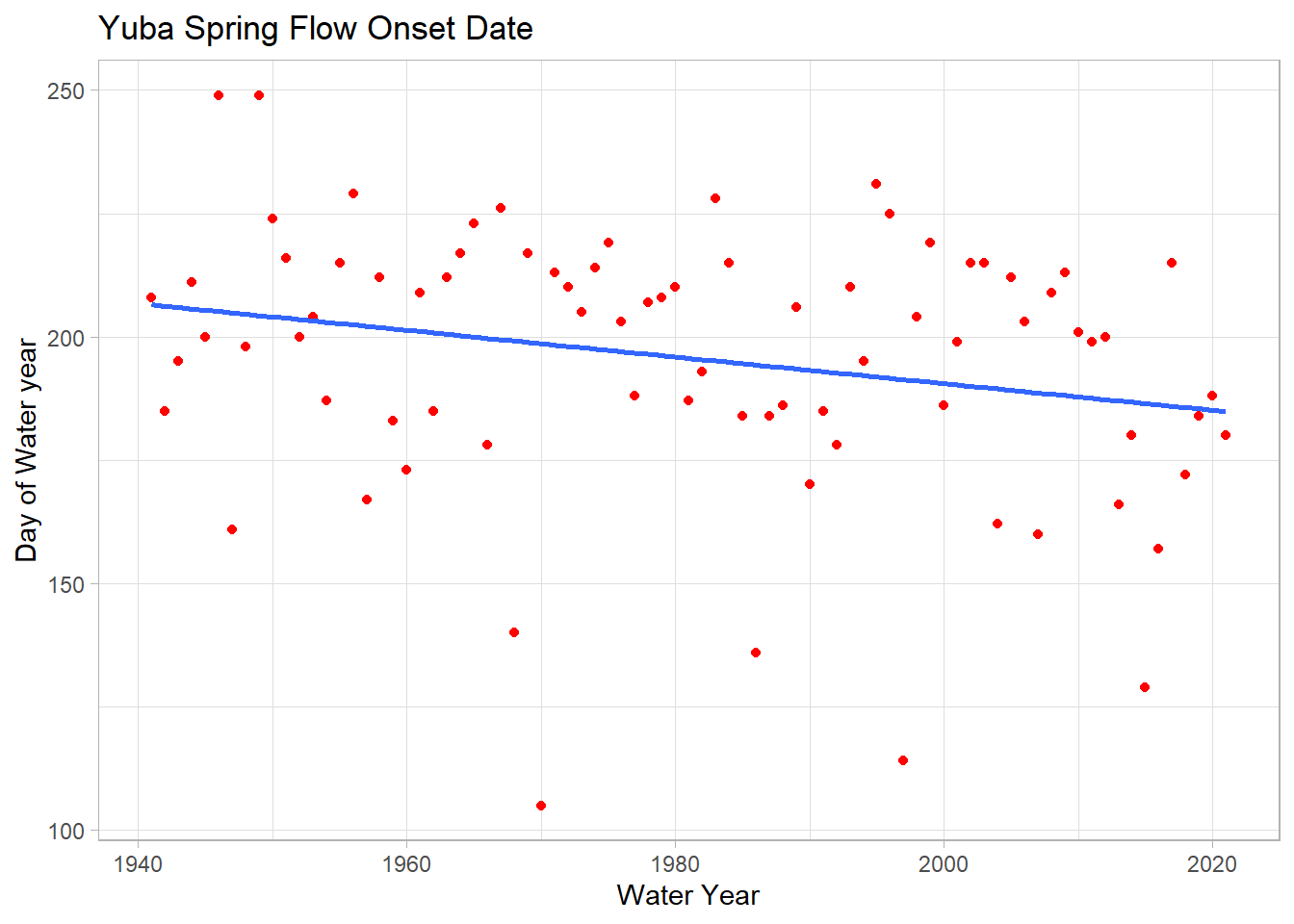
A few test annual hydrographs to make sure the function is working properly.
yuba_wy2021 <-filter(yuba, waterYear == 2021) # subset wy 2021
melt_date <-melt_onset_df$spring_flow_dowy[which(melt_onset_df$waterYear == "2021")]
# for wy2021
ggplot(yuba_wy2021, aes(y = discharge_cfs, x = dowy))+
geom_line(size = .7, col = "green") + # change width, set color
geom_vline(xintercept = melt_date, col = "red") + # date calculated
labs(title="Yuba near Goodyears Bar,CA Discharge WY 2021",
y="Discharge (cfs)", x="Date")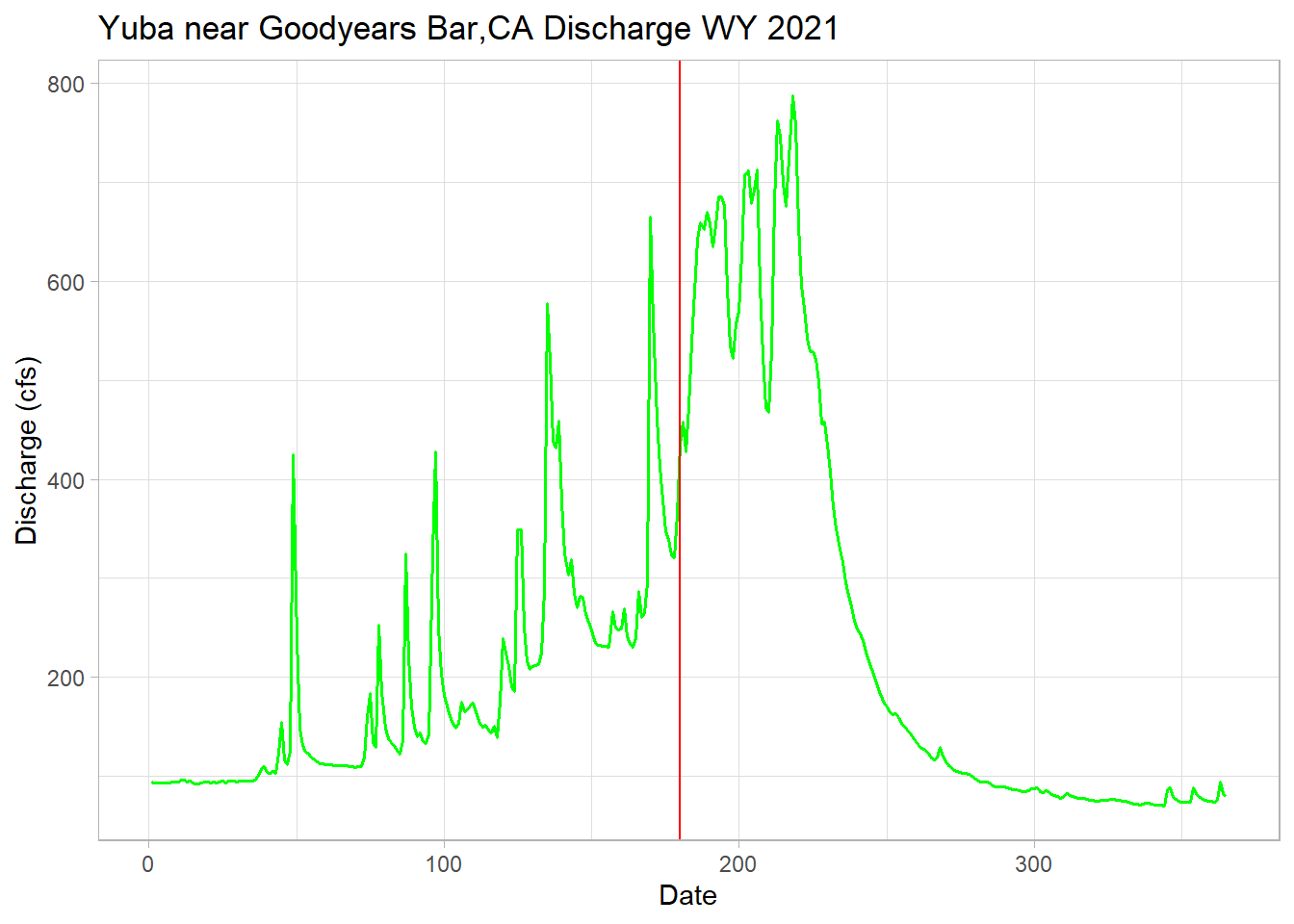
# 1970 has the earliest calculated date of 105 or January 15th!
min <-min(melt_onset_df$spring_flow_dowy)
yuba_wy1970 <-filter(yuba, waterYear == 1970) # low year
# plot to check our function is being reasonable here
# and it is, shows the variability in the hydroclimatic system
ggplot(yuba_wy1970, aes(y = discharge_cfs, x = dowy))+
geom_line(size = .7, col = "cyan") + # change width, set color
geom_vline(xintercept = min, col = "red") + # date calculated
labs(title="Yuba near Goodyears Bar,CA Discharge WY 1970",
y="Discharge (cfs)", x="Date")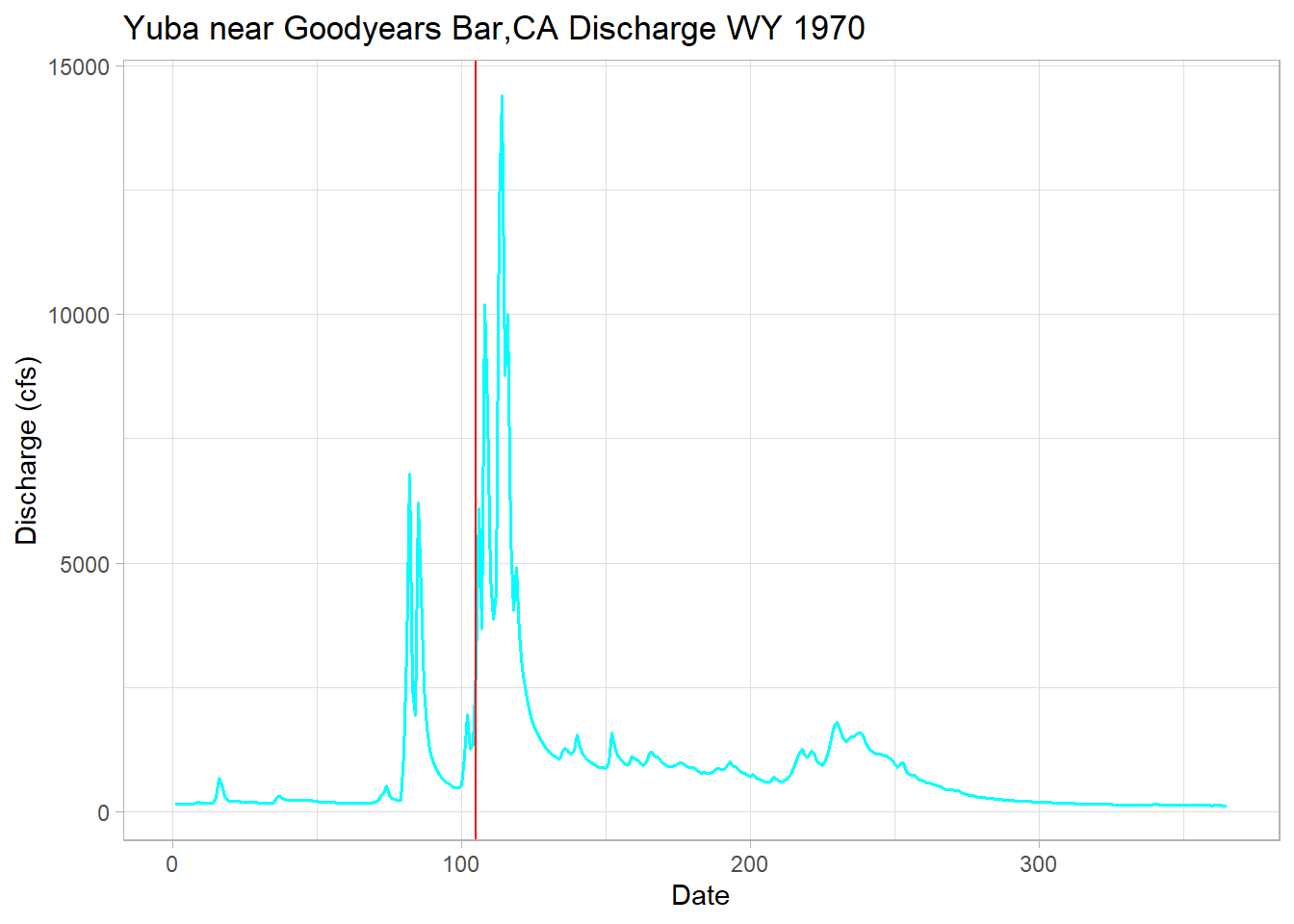
Mann-Kendall/Sen’s Slope Trend Analysis
We estimated the trend line on the above spring flow timing plot from a linear regression. This statistical test assumes the data a normal distribution, which is rarely the case in hydrology or many earth science fields. We’ll turn to the Mann-Kendall (MK) test, which does not require a normal distribution. We’ll then estimate the trend’s slope using the Thiel-Sen estimator or Sen’s Slope.
# test the data for normality
hist(melt_onset_df$spring_flow_dowy, breaks = 30)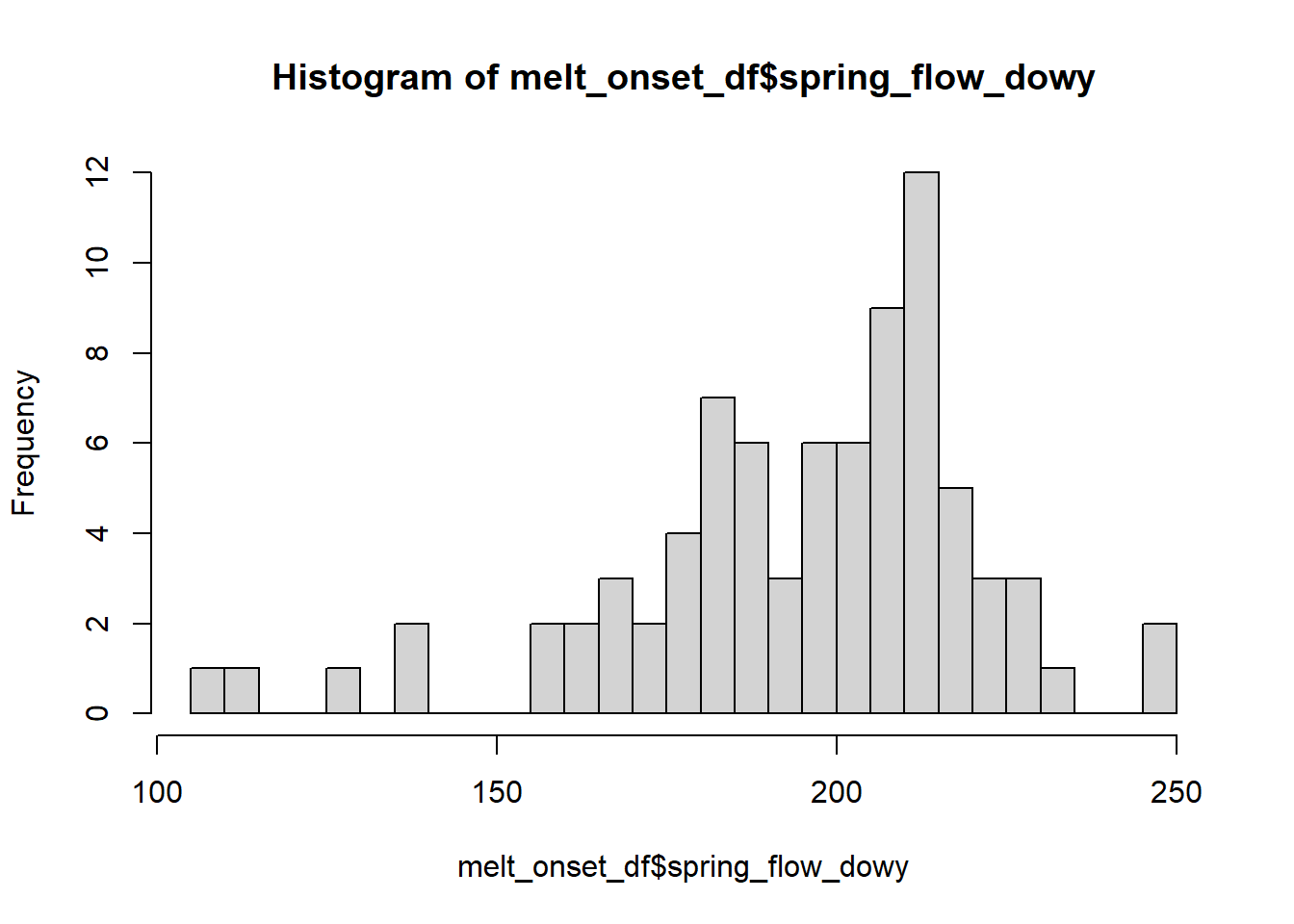
# but let's use a Shapiro test to check for real
shapiro.test(melt_onset_df$spring_flow_dowy) ##
## Shapiro-Wilk normality test
##
## data: melt_onset_df$spring_flow_dowy
## W = 0.92861, p-value = 0.0002267P-value is below .05, therefore we reject the null hypothesis of a normal distrubution.
# We can turned to the Mann-Kendall trend test, which is non-parametric, not requiring a normal dist
# this only tells us if there is a significant trend, not the estimated slope
mk_results <-trend::mk.test(melt_onset_df$spring_flow_dowy)
print(mk_results) # significant##
## Mann-Kendall trend test
##
## data: melt_onset_df$spring_flow_dowy
## z = -2.2237, n = 81, p-value = 0.02617
## alternative hypothesis: true S is not equal to 0
## sample estimates:
## S varS tau
## -546.0000000 60070.0000000 -0.1695685# for a slope estimate we uses the Sen's slope function
sens_result <-trend::sens.slope(melt_onset_df$spring_flow_dowy)
print(sens_result)##
## Sen's slope
##
## data: melt_onset_df$spring_flow_dowy
## z = -2.2237, n = 81, p-value = 0.02617
## alternative hypothesis: true z is not equal to 0
## 95 percent confidence interval:
## -0.48148148 -0.02040816
## sample estimates:
## Sen's slope
## -0.2400926slope_est <-as.numeric(sens_result[[1]]) # slope estimate
# the trend package only gives us slope, not a y-int estimate for plotting
# we'll use the zyp package for that
y_int_results <-zyp::zyp.sen(spring_flow_dowy ~ waterYear, melt_onset_df) # y comes first!!
print(y_int_results) # inspect##
## Call:
## NULL
##
## Coefficients:
## Intercept waterYear
## 677.7401 -0.2401y_int <-y_int_results$coefficients[[1]] # pull out y-int estimate for plotingPlot the data with the significant trend
# not let's plot the data with our MK estimate trend, instead of lm one from ggplot
ggplot(melt_onset_df, aes(y = spring_flow_dowy, x = waterYear)) +
geom_point(col = "red")+
# geom_smooth(method = "lm", se = FALSE) +
# use info from our MK and Sen's test to graph the trend line
geom_abline(intercept = y_int, slope = slope_est, color="blue", size=1.2) +
labs(title="Yuba Spring Flow Onset Date MK Trend",
y="Day of Water year", x="Water Year")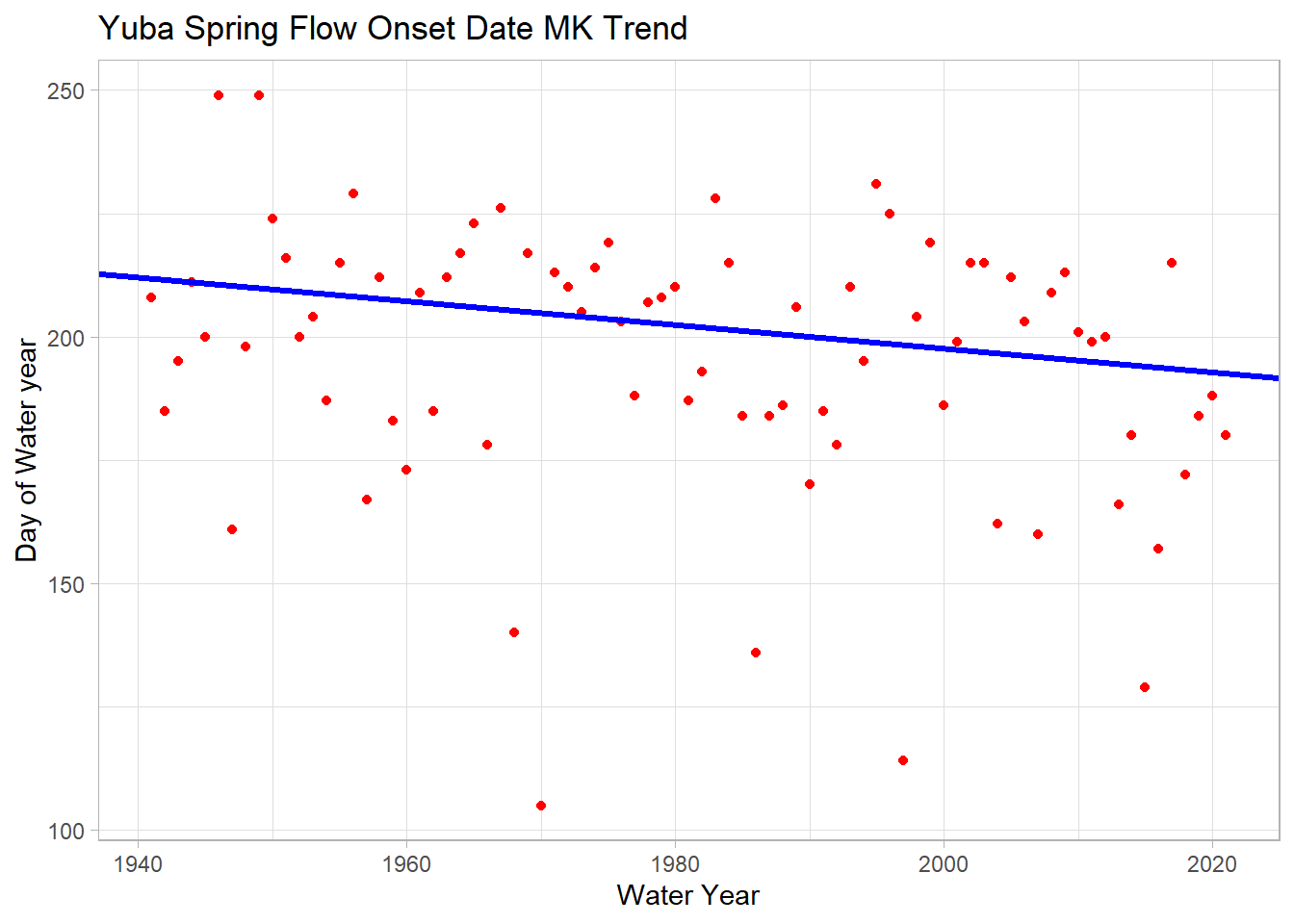
We see a significant trend of 2.4 days/decade earlier spring streamflow!
Second Streamflow Analysis Example
For this section, we’ll also work through a trend analysis using USGS streamflow data, using the same procedures as Jack has already shown you. With this dataset I will demonstrate other options for forecasting with an ARIMA model and performing change point detection.
This map shows the location on the Martin Creek gauge, just north and east of Paradise Valley, Nevada (green marker).
This gauge was selected because two fires (2011, 2018) have impacted the watershed recently and there could be an opportunity to see changes in the trend or seasonality of the data.
We’ll use the same procedures already shown via the dataRetrevial package to download daily stream gauge data.
First, we will visualize the time series. Conveniently, there are 100 years of data for this gauge.
# quick test plot to visualize the time series
plot(martin$Date, martin$discharge_cfs, type = "l",
main = "Martin Creek Discharge,NV",
ylab = "Discharge (cfs)",
xlab = "Date")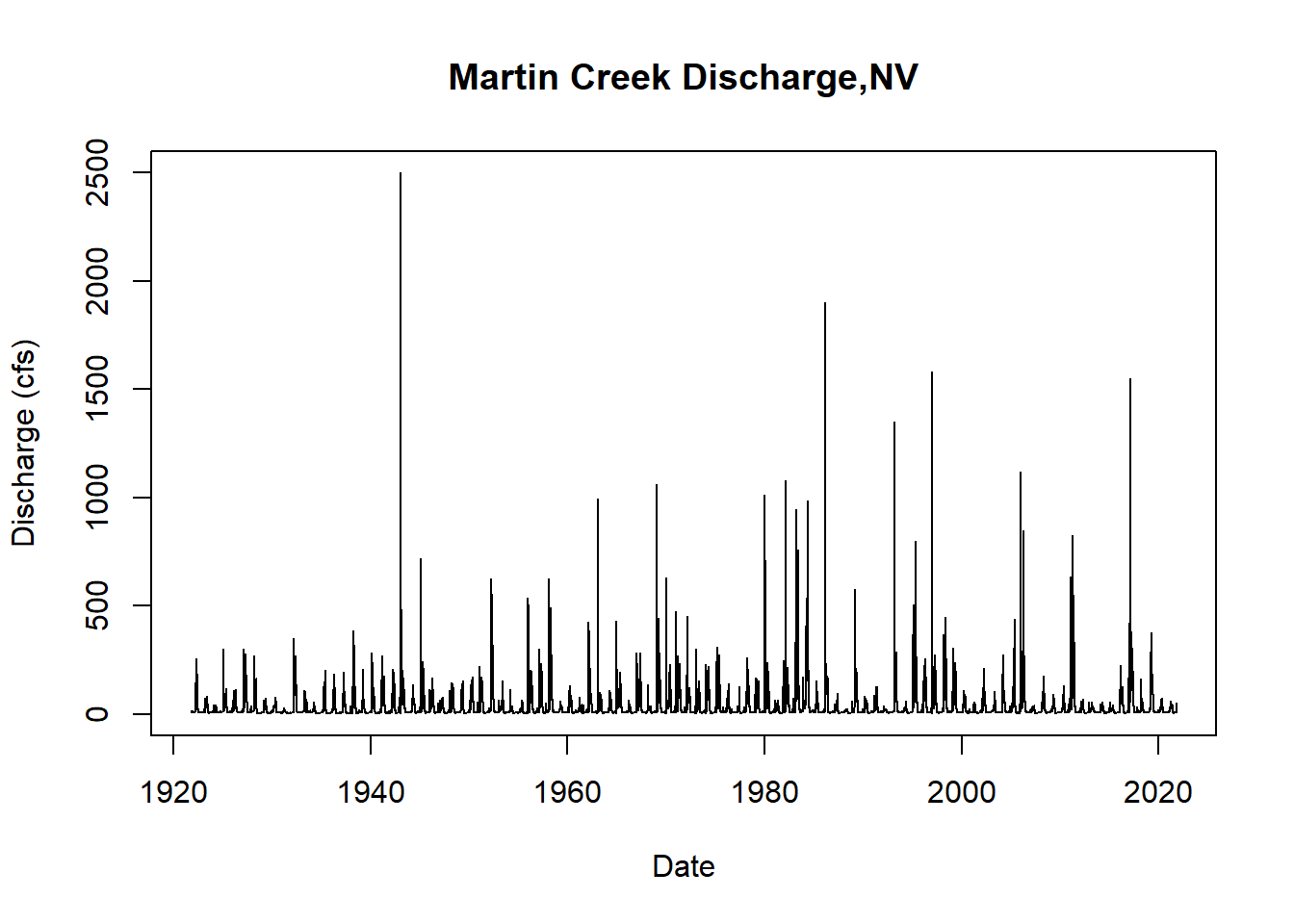
Next we will convert the average daily cfs recordings to a time series object and take a look at the summary of the data.
df_day_ts <- ts(data = martin$discharge_cfs, frequency = 365.25, start = c(1921,10), end= c(2021,10))
summary(df_day_ts)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 2.00 7.00 10.00 34.05 32.00 2500.00Time Series Decomposition
Now we’ll proceed with decomposing the data to visualize the trend, seasonality, and residuals. In order to decompose, we need to select either an additive or multiplicative model. In this case, the data fits an additive model. If you aren’t sure which case your data falls into, you can calculate the sums of squares of the autocorrelation function for the additive decomposition and the multiplicative decomposition of the data to see which model gives you the smallest sum of squares value. In this case the additive decomposition achieves the smallest sum of squares.
#decompose the data both ways
ddata <- decompose(df_day_ts, type = "additive")
ddatam <- decompose(df_day_ts, type = "multiplicative")
plot(ddata) #additive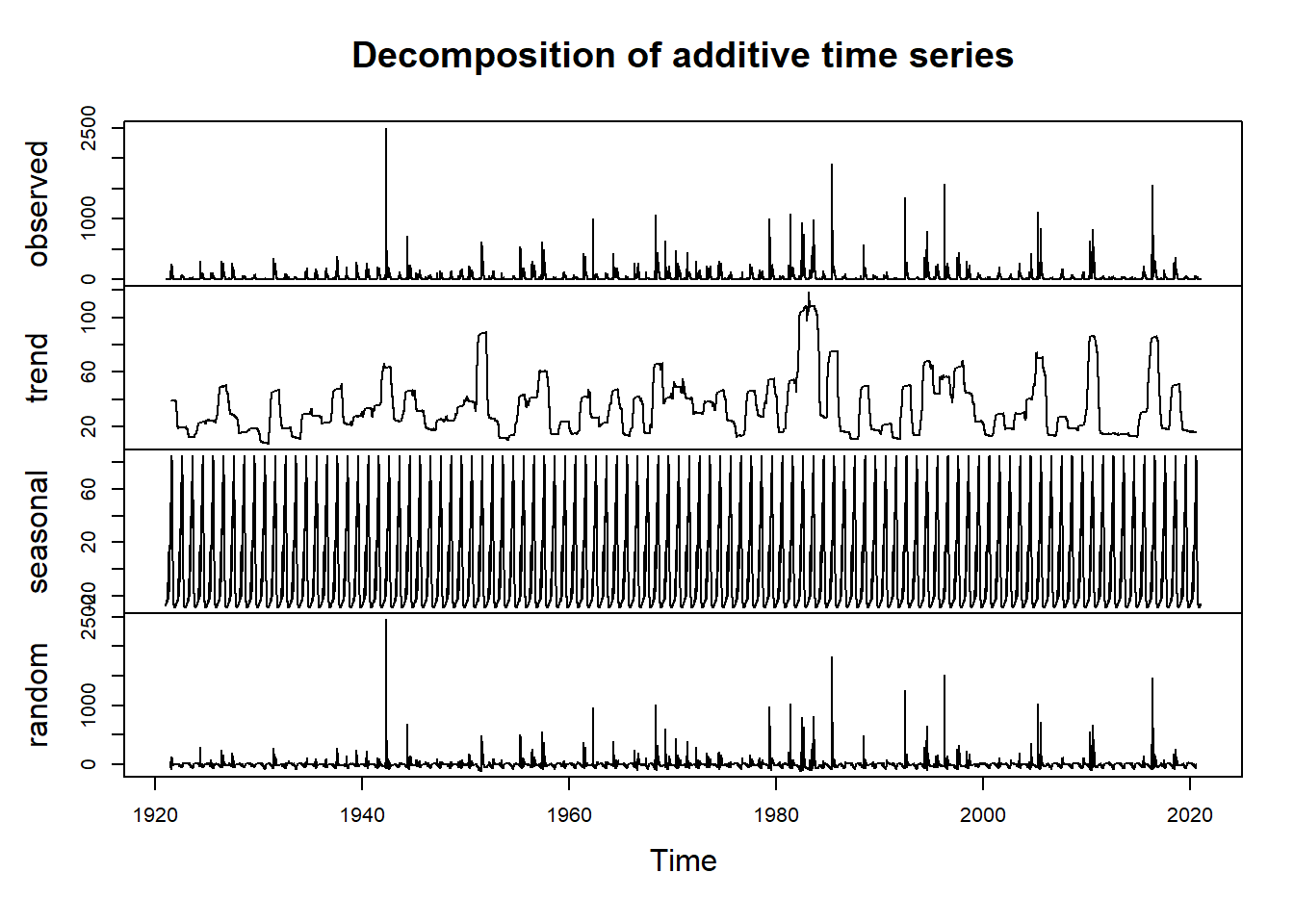
plot(ddatam) #multiplicative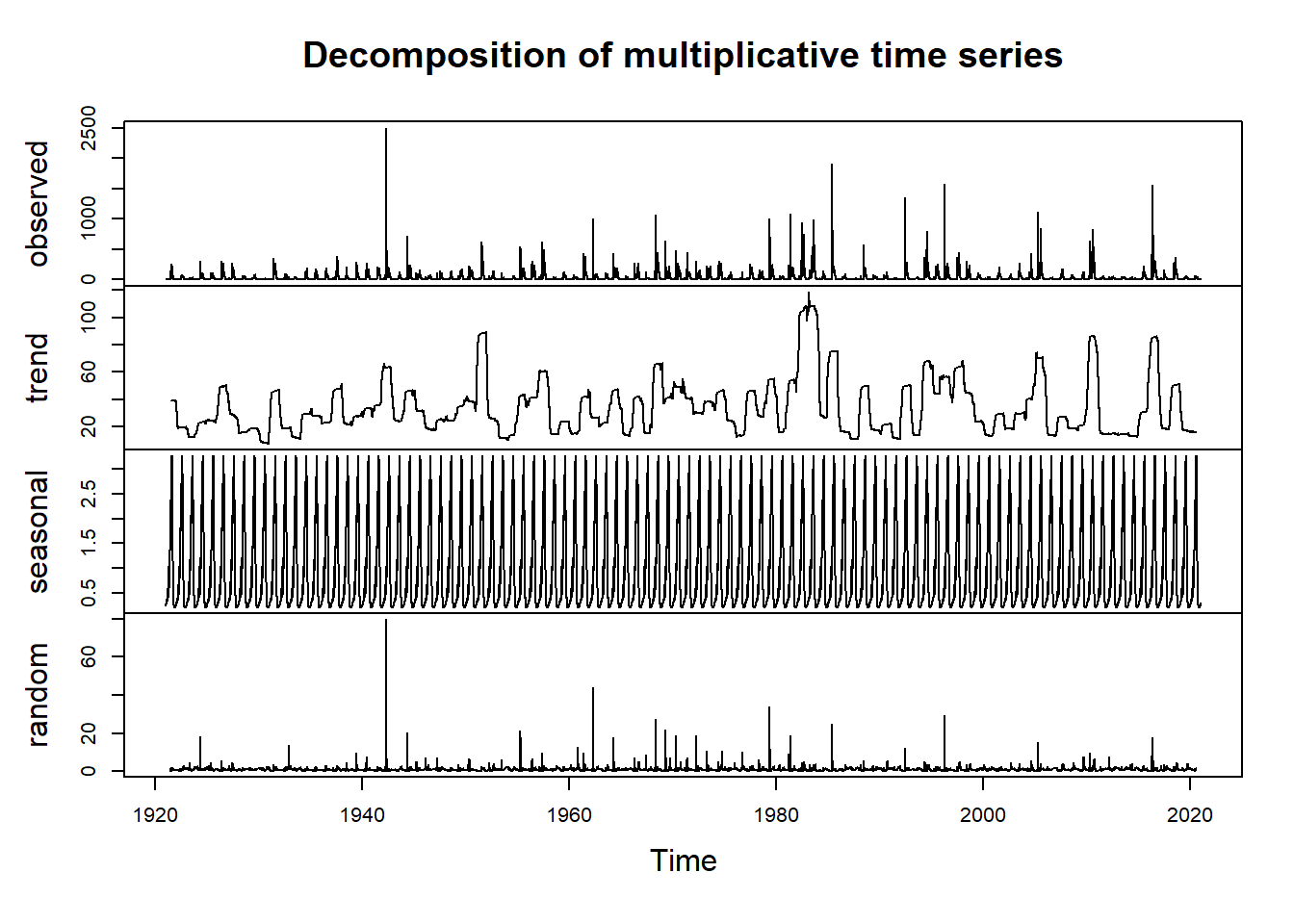
#compare which model has smaller sums of squares for the ACF of the residuals
add_info <- sum(acf(ddata$random, lag.max = length(ddata$random), na.action = na.omit)$acf^2)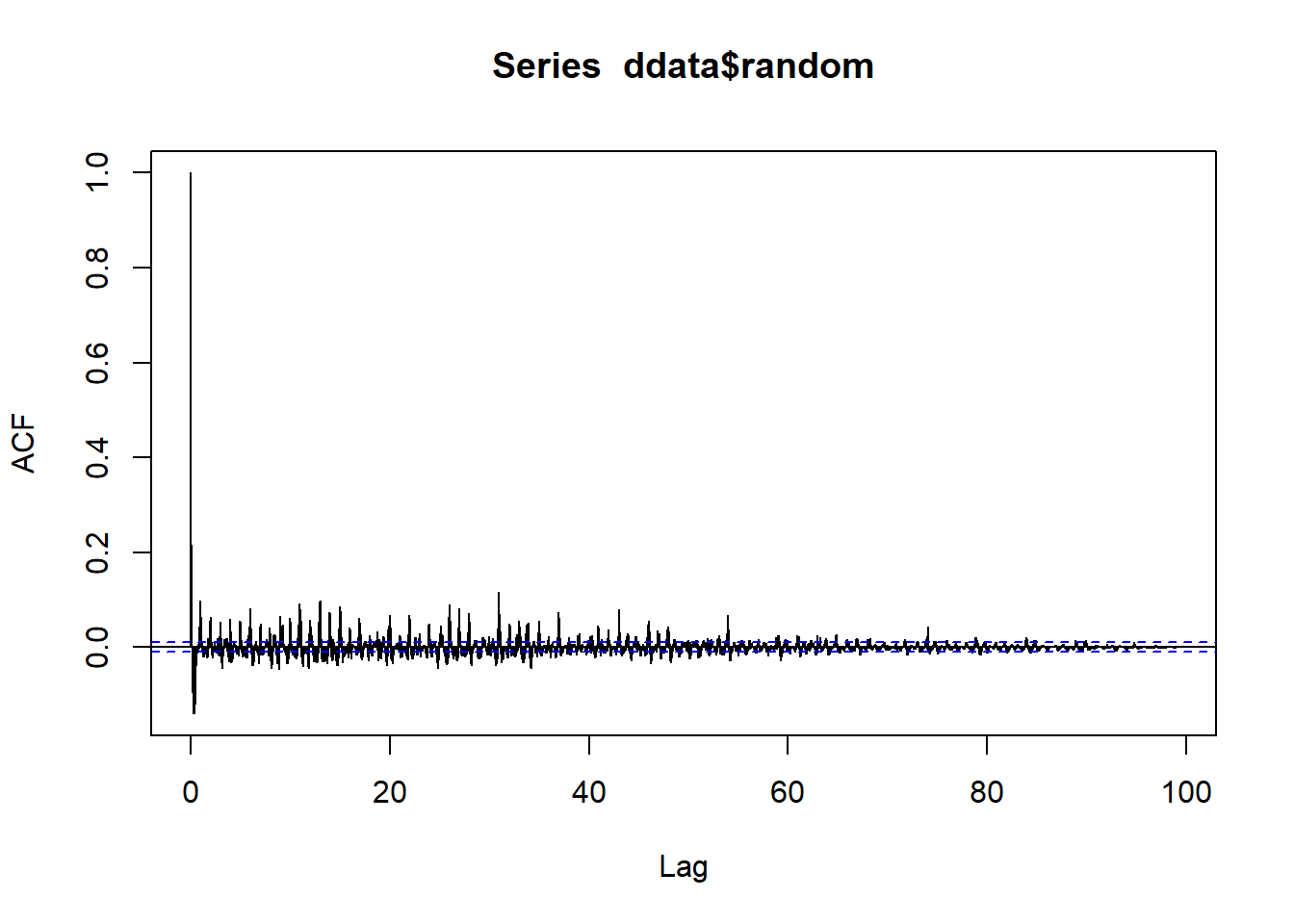
mult_info <- sum(acf(ddatam$random, lag.max = length(ddatam$random), na.action = na.omit)$acf^2)
add_info## [1] 14.77871#mult_info
#we will use ddata for the remainder of the demoLet’s visualize the decomposed data more closely by looking just at the trend component.
#Now we visualize our decomposed data and our trend component
#plot(ddata)
plot(ddata$trend)
abline(reg=lm(ddata$trend~time(ddata$trend)), col="red")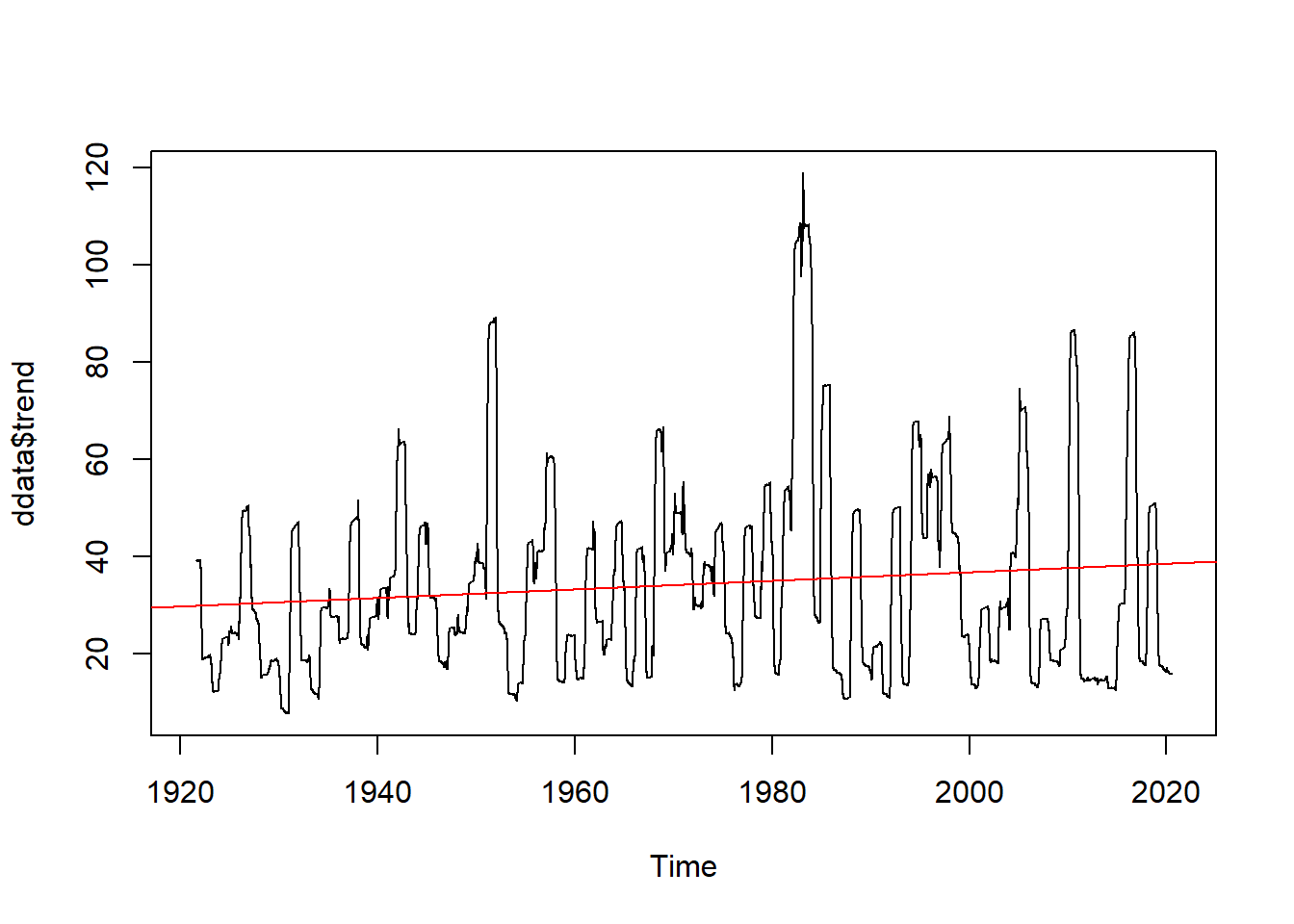
We see we might have a positive trend and we might have seasonality to our data (as we would expect).
Testing Time Series Forecasing Assumptions
In order to build time series forecasting models, the data has to meed the assumptions of the model. Forecasting models, whether ARMA (autoregressive moving average) or ARIMA (autoregressive integrated moving average), rely on data that is well-behaved: stationary (no trend), has uniform variance, and is independent, or doesn’t exhibit strong temporal autocorrelation.
We can perform several tests to check these assumptions about our data before building a forecasting model.
# examine the data for normality
hist(ddata$trend, breaks = 30)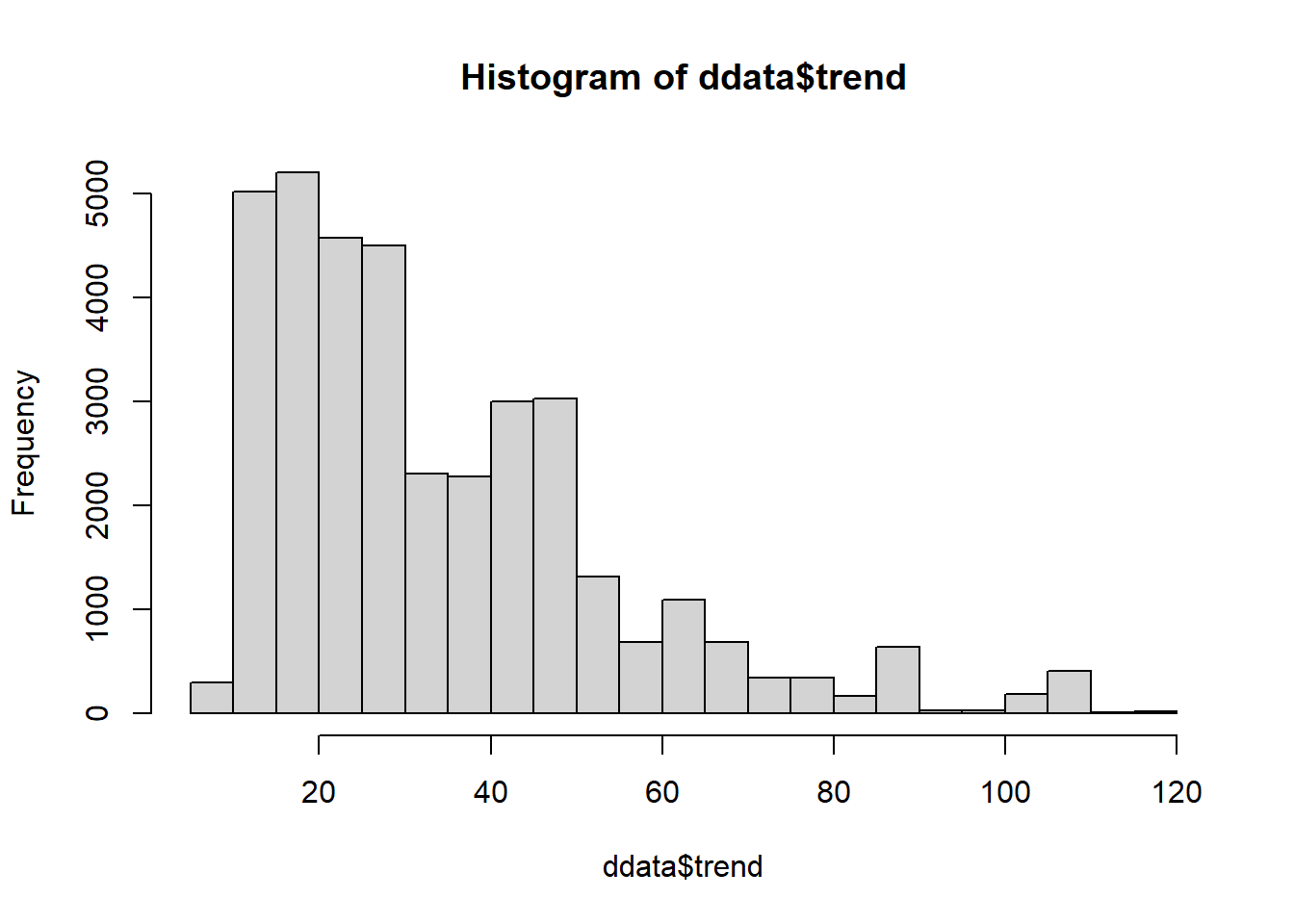
# try autocorrelation function (ACF) (Autoregressive process) and the partial autocorrelation function (PACF) (Moving Average process) to examine the data
acf(df_day_ts,lag.max = length(df_day_ts),
xlab = "lag #", ylab = 'ACF',main='ACF results in very gradual attenuation') #possible non-stationarry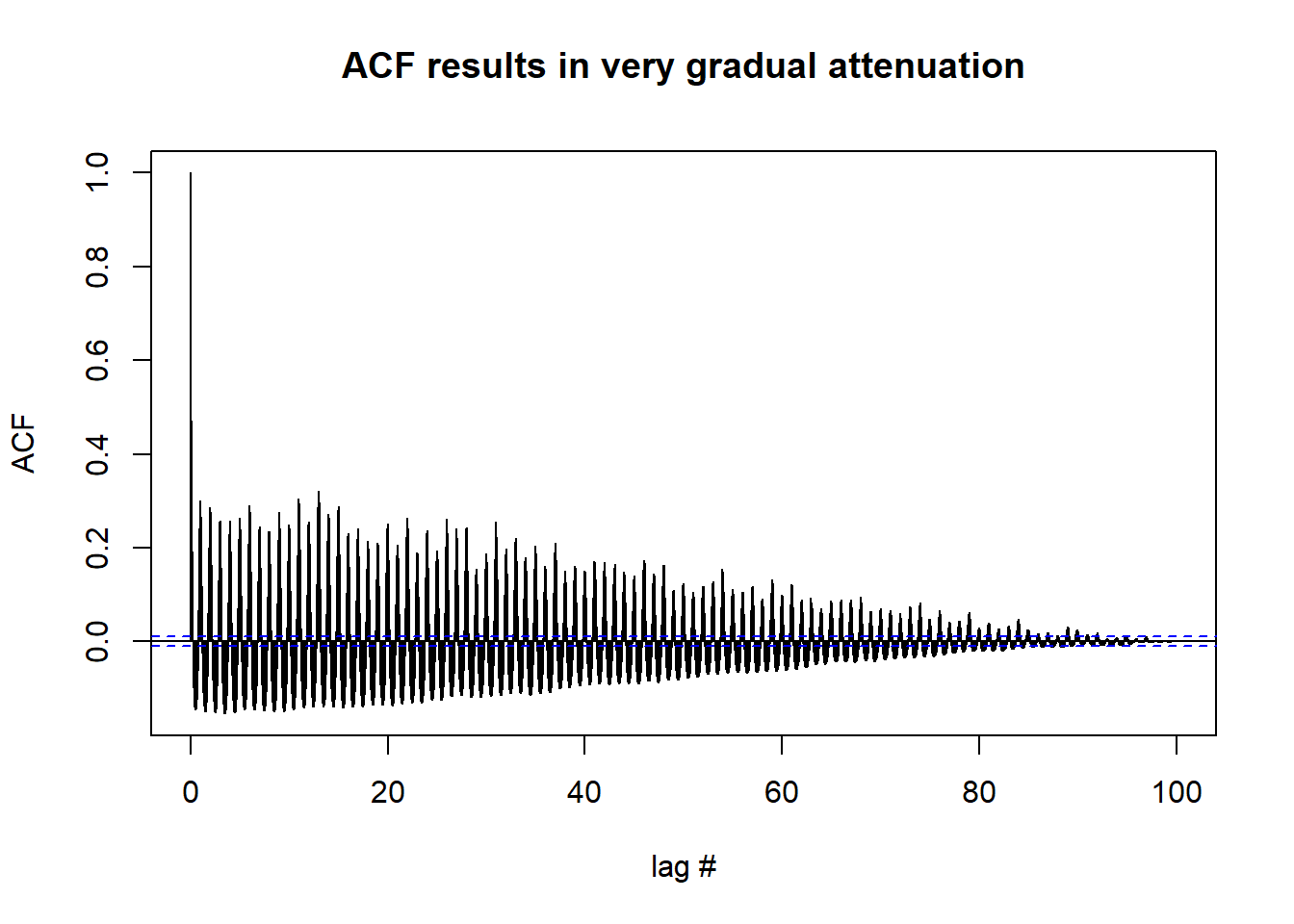
pacf(df_day_ts, lag.max = length(df_day_ts), xlab = "lag #", ylab = 'PACF',main='PACF results in rapid dampening') #possible stationary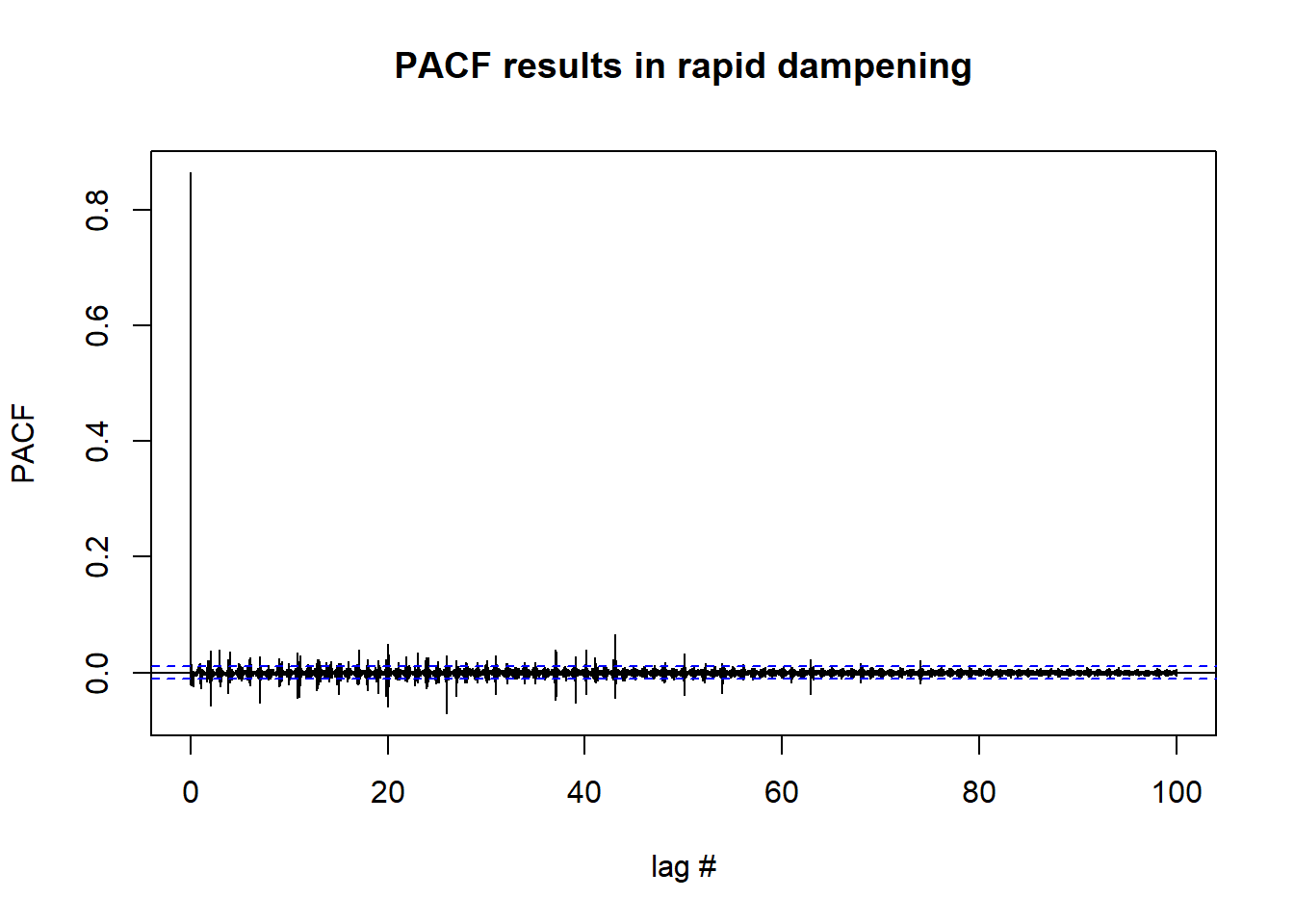
#Ljung-Box test for independence
#the Ljung-Box test examines whether there is significant evidence for non-zero
#correlations at given lags. If p-value >0.05, we accept the null hypothesis of independence.
lag.length = 25
options(warn=-1)
Box.test(df_day_ts, lag=lag.length, type="Ljung-Box")##
## Box-Ljung test
##
## data: df_day_ts
## X-squared = 314519, df = 25, p-value < 2.2e-16#p-value suggests we should reject the null and assume data is not independent
#Another test we can conduct is the Augmented Dickey–Fuller (ADF) t-statistic
#test to find if the series has a unit root. Non-stationary data will have a large p-value.
tseries::adf.test(df_day_ts)##
## Augmented Dickey-Fuller Test
##
## data: df_day_ts
## Dickey-Fuller = -16.584, Lag order = 33, p-value = 0.01
## alternative hypothesis: stationary#this test suggests that we might have stationary data
#A fourth test we can use to check assumptions is to check for stationarity or trend is the Kwiatkowski-Phillips-Schmidt-Shin (KPSS) test.
tseries::kpss.test(df_day_ts, null="Level") #results in p-value = 0.01, reject null##
## KPSS Test for Level Stationarity
##
## data: df_day_ts
## KPSS Level = 0.7853, Truncation lag parameter = 17, p-value = 0.01#this test suggests that our data might not be stationaryTesting For Differencing Needed to Remove Trend and/or Seasonality
We can use the forecast package to test how many lag differences we may need to do in order for our data to become stationary.
forecast::ndiffs(df_day_ts) # number of differences need to make it stationary## [1] 0forecast::nsdiffs(df_day_ts) # number for seasonal differencing needed## [1] 0#if we needed to difference (as some of our tests tell us we might):
stationaryCFS <- diff(df_day_ts, differences=1)
#examine differenced data
plot(stationaryCFS, type="l", main="Differenced and Stationary") # appears to be stationary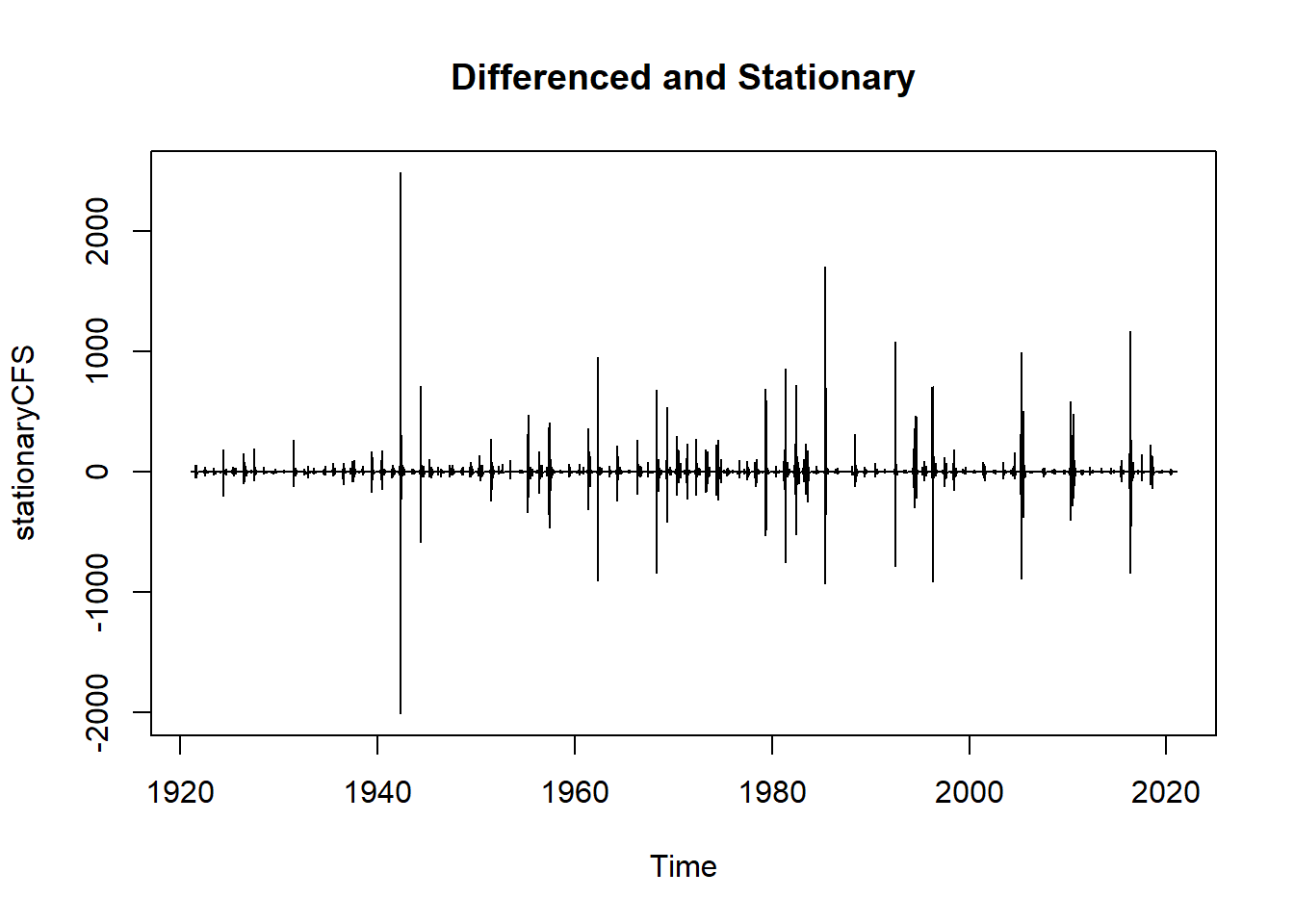
hist(stationaryCFS)
And we can verify if our differencing procedure above worked or not.
lag.length = 25
options(warn=-1)
Box.test(stationaryCFS, lag=lag.length, type="Ljung-Box") #still autocorrelated##
## Box-Ljung test
##
## data: stationaryCFS
## X-squared = 2148.7, df = 25, p-value < 2.2e-16tseries::adf.test(stationaryCFS) #stationary##
## Augmented Dickey-Fuller Test
##
## data: stationaryCFS
## Dickey-Fuller = -42.236, Lag order = 33, p-value = 0.01
## alternative hypothesis: stationarytseries::kpss.test(stationaryCFS) #stationary##
## KPSS Test for Level Stationarity
##
## data: stationaryCFS
## KPSS Level = 0.00059564, Truncation lag parameter = 17, p-value = 0.1#Our data might not meet the normality assumption and it is still autocorrelated. We may need to mean-center our data to reduce problems with forecasting and reduce problems due to temporal autocorrelationARIMA Model Development
Now that we are fairly certain our data at least meets the stationary assumption, we will go ahead and fit an ARIMA model using the auto.arima function. We are going to box-cox transform the data to reduce the effects of our non-normal distribution on fitting the model.
options(warn=-1)
mymodel <- forecast::auto.arima(stationaryCFS, lambda = "auto", parallel = TRUE, num.cores = 8)
mymodel## Series: stationaryCFS
## ARIMA(3,0,1) with zero mean
## Box Cox transformation: lambda= 1.246594
##
## Coefficients:
## ar1 ar2 ar3 ma1
## 0.4472 0.0292 -0.0172 -0.8746
## s.e. 0.0070 0.0061 0.0059 0.0047
##
## sigma^2 estimated as 17385: log likelihood=-230128.6
## AIC=460267.1 AICc=460267.1 BIC=460309.7Forecasting using an ARIMA model
Now we can use the tools in the forecast package to forecast our stream gauge data into the future.
#let's try forecasting now that we have an ARIMA model built
fit <- forecast::Arima(df_day_ts, c(3,0,1)) #ARIMA model shows three coefficients for the AR component, 0 seasonal differences, and 1 coefficient for the MA component
plot(forecast::forecast(fit))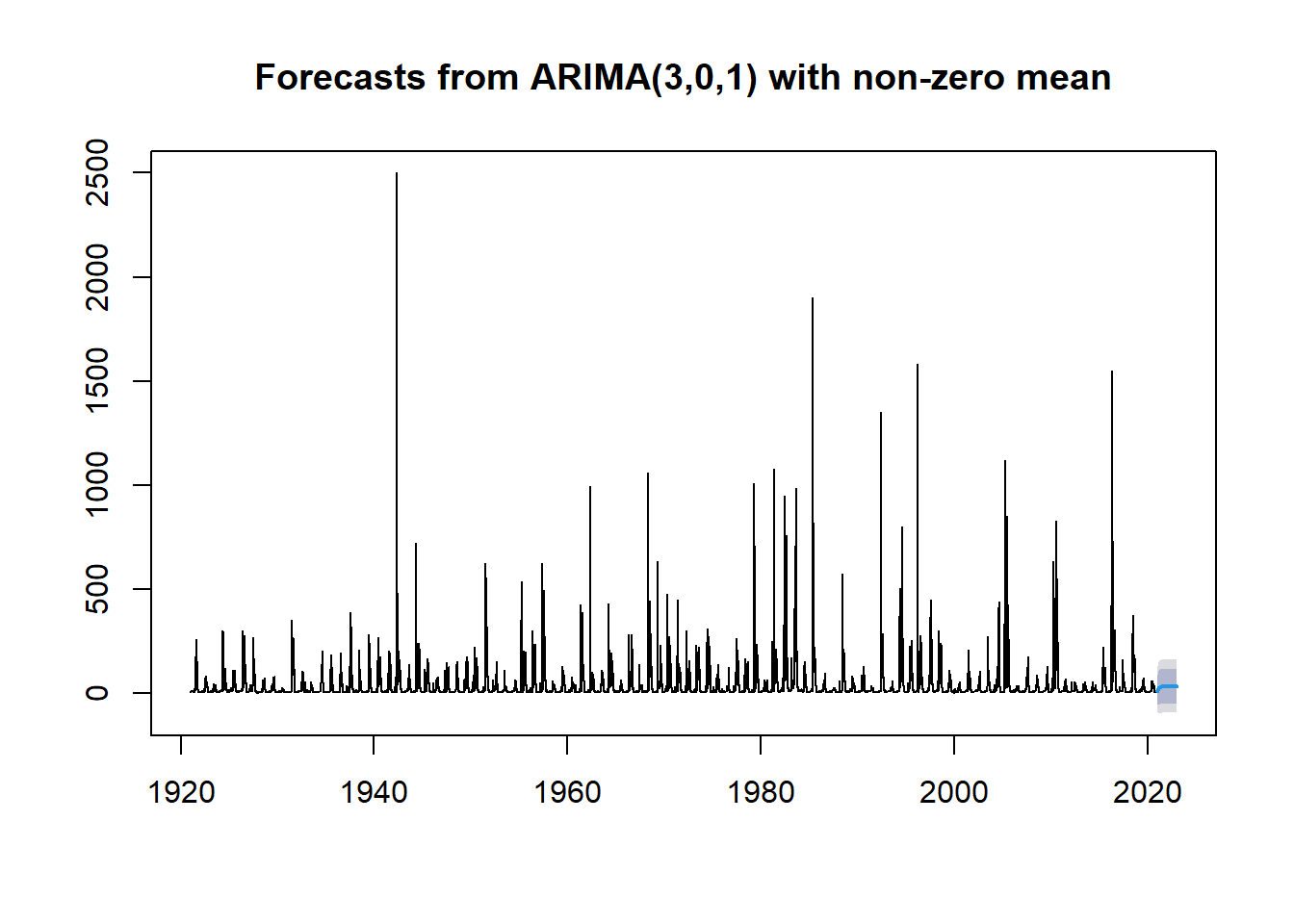
Change Point Detection
Well that is a pretty poor forecast, but what if what we really want to know is if the fires that happened in 2011 and 2018 might have a large enough effect to cause a change in trend or a change in mean run-off, causing an increase in CFS at the gauge.
Let’s examine how to detect if change points might exist using the changepoint package.
#we write a function that will help us look for the correct penalty value to set in our change point analysis
cptfn <- function(data, pen) {
ans <- changepoint::cpt.mean(data, test.stat="Normal", method = "PELT", penalty = "Manual", pen.value = pen)
length(cpts(ans)) +1
}
# run our cptfn function expecting there is a signal with a known change point
pen.vals <- seq(0, 12,.2) #set some penalty values to use in the elbow plot
elbowplotData <- unlist(lapply(pen.vals, function(p)
cptfn(data = df_day_ts, pen = p))) #apply our function on the data
#and now we plot the penalty parameters as a function of the time series
plot(pen.vals,elbowplotData,
xlab = "PELT penalty parameter",
ylab = " ",
main = " ")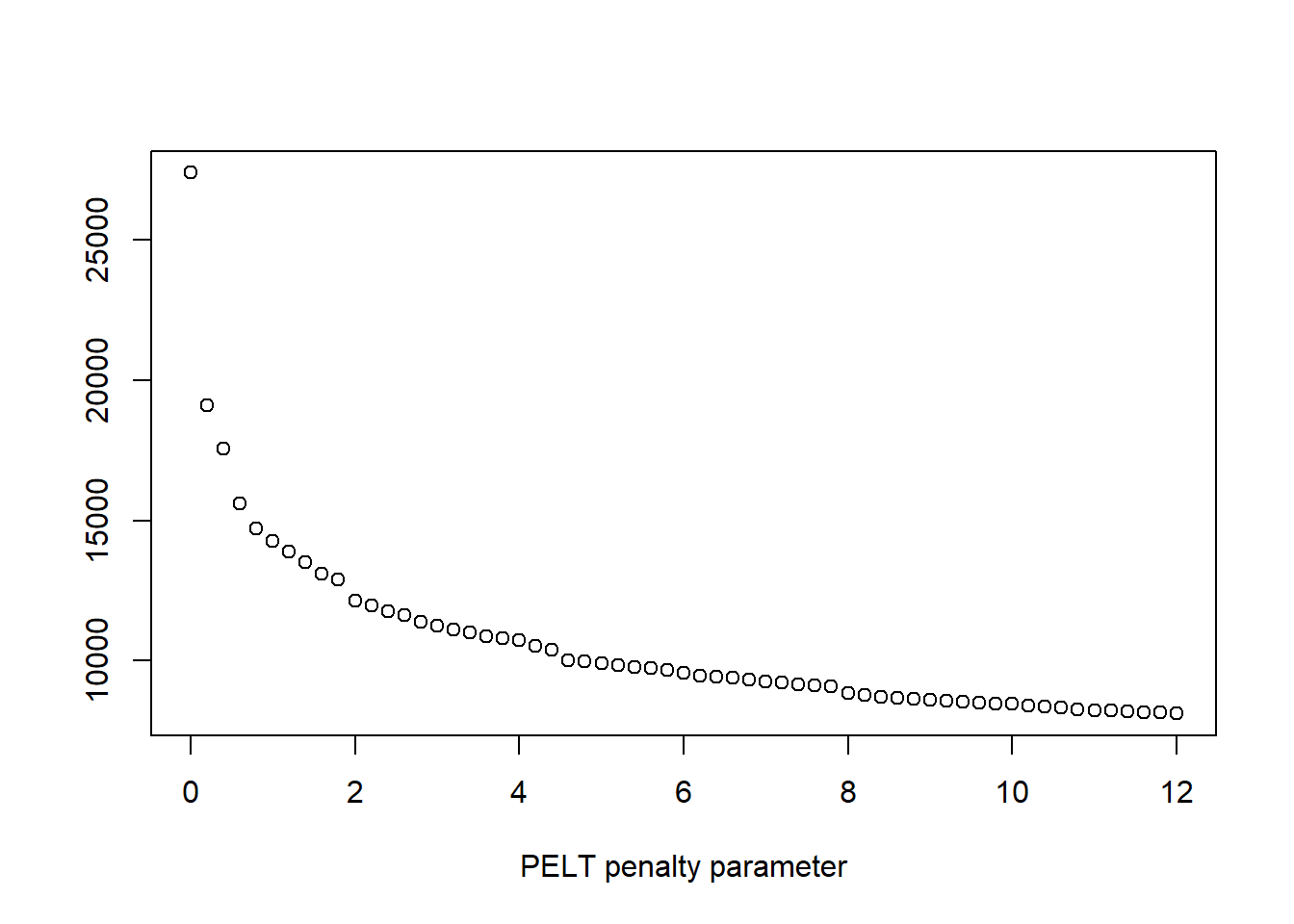
#look at the graphs, especially the PELT Penalty Parameter to determine
#where the change point might be
penalty.val <- 6 # this value is determined from elbow plots
#next we use cpt.mean and the SegNeigh method with a max number of change points set to 4 to detect change points in the data
options(warn=-1)
cptm_data <- changepoint::cpt.mean(df_day_ts, penalty='Manual',pen.value=penalty.val,method='SegNeigh', Q=4)
cpts_dat <- changepoint::cpts(cptm_data) # change point time points
cpts_dat #gives us the time points## [1] 22415 22842 22897We really want to visualize the data. It is much easier to see the change point means on the decomposed trend data than it is to see it on the original data, so we will perform the above for the decomposed trend data as well and see what differences occur.
trend_narm <- na.omit(ddata$trend) #decomposed trend data without the NA's
options(warn=-1)
cptm_trend <- changepoint::cpt.mean(trend_narm, penalty='Manual',pen.value=penalty.val,method='SegNeigh', Q=4)
cpts_trnd <- changepoint::cpts(cptm_trend) # change point time points
cpts_trnd #gives us the time points## [1] 5684 22150 22873plot(cptm_data,
xlab = "Time",
ylab = "Avg. Daily Discharge (cfs)",
main = "Change in Mean Signal")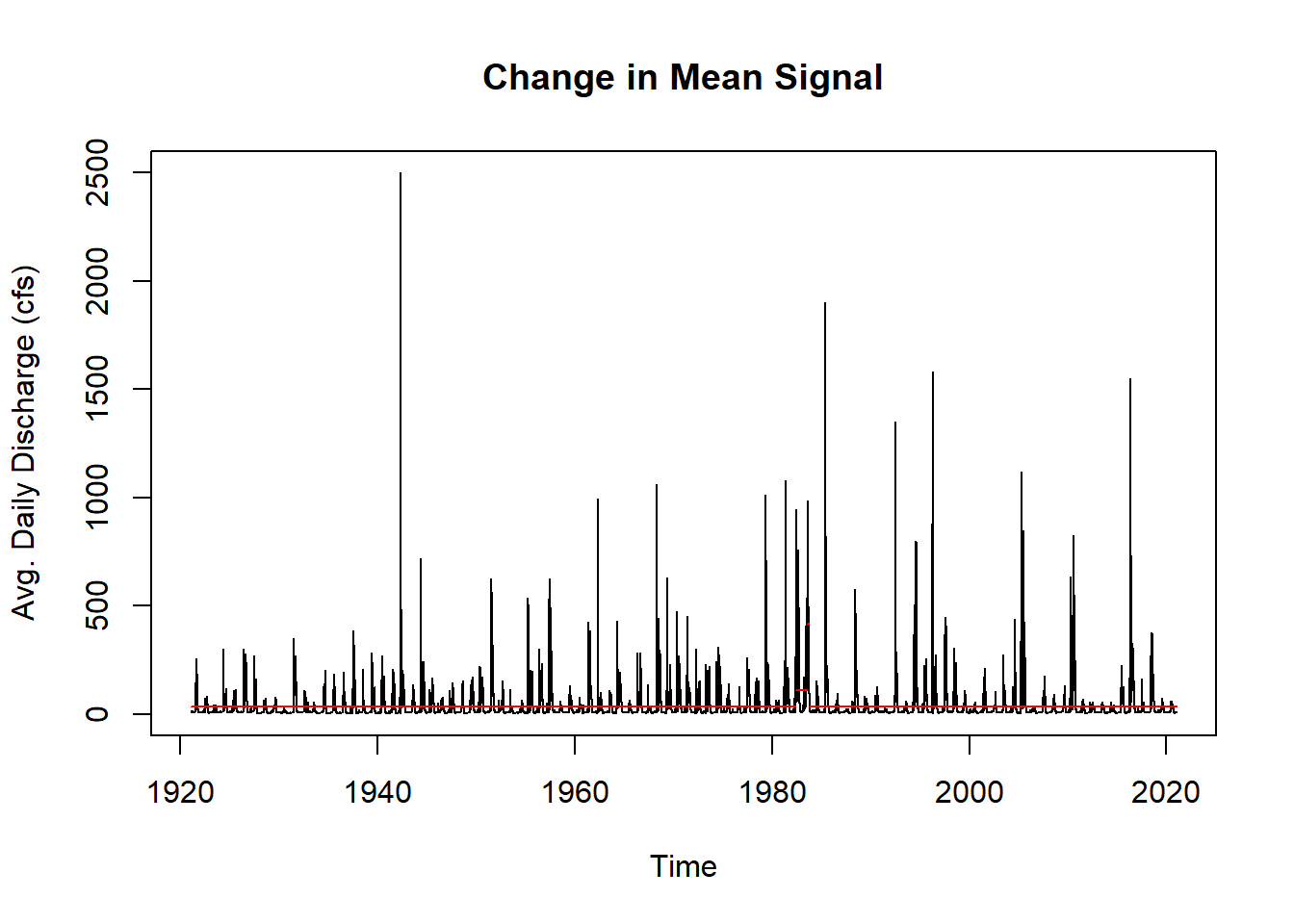
plot(cptm_trend,
xlab = "Time",
ylab = "Decomposed Trend of CFS",
main = "Change in Mean Signal")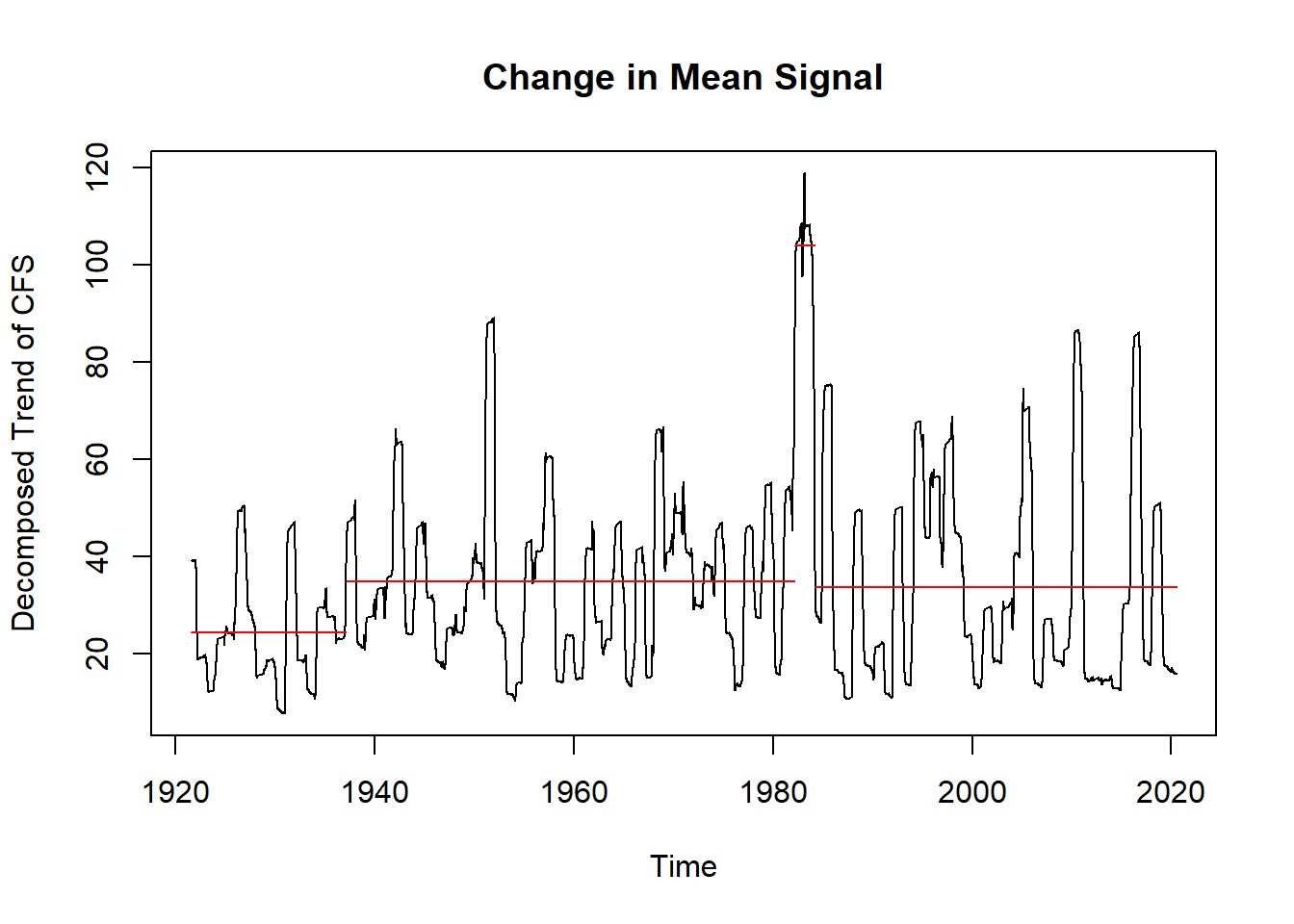
This concludes the three demonstrations of how to work with time series data. We hope that you now have some ideas on how to tackle time series analysis with your own datasets.
Conclusions
- Time series analysis is a huge topic with a wide array of uses.
- Time series data can be analyzed using a variety of different packages in R.
- Much of the time series literature focuses on econometrics and forecasting which is often not relevant to ecologists/hydrologists.
- Many researchers fail to properly explore the nature of their time series data and subsequently get their papers rejected.
- We’re living in a no-analog, non-stationary time. Previous resource-management methods assumed stationarity and we now have to adapt.

References and Resources
Coghlan, A. A Little Book of R For Time Series. Release 0.2. Sep 10, 2018. https://a-little-book-of-r-for-time-series.readthedocs.io/en/latest/src/timeseries.html. Accessed on 11/1/2021.
Hyndman, R.J. and G. Athanasopoulos. Forecasting: Principles and Practice. 2nd Ed. OTexts: Melbourne, Australia. OTexts.com/fpp2. Accessed on 11/1/2021.
McCleary, R., D. McDowall, B.J. Bartos. Design and Analysis of Time Series Experiments. Oxford University Press, New York, NY. 2017. 359 p.
Perry, J.N, R.H. Smith, I.P. Wolwod, and D.R. Morse, Ed. Chaos in Real Data: the analysis of non-linear dynamics from short ecological time series. Kluwer Academic Publishers, Dordrecht, Netherlands. 2000. 218 p.
Yaffee, R. and M. McGee. Introduction to Time Series Analysis and Forecasting with Applications of SAS and SPSS. Academic Press. San Diego, CA. 2000. 511 p.
Useful Weblinks for Time Series Analysis
https://www.marinedatascience.co/blog/2019/09/28/comparison-of-change-point-detection-methods/
http://r-statistics.co/Time-Series-Analysis-With-R.html
https://www.r-bloggers.com/2017/02/is-my-time-series-additive-or-multiplicative/
https://rcompanion.org/handbook/F_13.html #Mann-Kendall non-parametric test
http://rpubs.com/richkt/269797 #Stationarity testing
https://otexts.com/fpp2/ # Forecasting Principles and Practice, 2 ed.