ANOVA/MANOVA
Maria Sole Bonarota, Mona Farnisa, Ranae Zauner
Fall 2021
MANOVA
Here is the download link for the R script for this lecture: MANOVA script
Overview
- Introduction (Sole)
- ANOVA vs. MANOVA
- Assumptions of MANOVA
- Theory of ANOVA (Sum of Squares)
- Theory of MANOVA (Sum of Squares and Cross Product Matrices)
- One-way vs. Factorial
- Demo 1 – One-way MANOVA (Mona)
- Demo 2 – Factorial MANOVA (Ranae)
Introduction
MANOVA is an extension of ANOVA and assesses the effects of one or multiple groups on multiple dependent variables. ANOVA is widely used in life science and it allows us to determine whether the means between three or more groups are statistically different. ANOVA is the statistical analysis that we should use when we want to test a particular hypothesis, such as how different groups respond to a certain effect.
One-way ANOVA compares the effects of one group on one dependent variable, while Two-way and Factorial ANOVA compare the effects of two and more groups and their interaction terms on one dependent variable.
What is the purpose of ANOVA? To determine whether the group variable(s) can affect the outcome variable.
library(heplots)## Warning: package 'heplots' was built under R version 4.1.1## Loading required package: car## Loading required package: carDatadata(RootStock) # Dataset from an experiment comparing apple trees from from six different root stocks from 1918-1934.
str(RootStock)## 'data.frame': 48 obs. of 5 variables:
## $ rootstock: Factor w/ 6 levels "1","2","3","4",..: 1 1 1 1 1 1 1 1 2 2 ...
## $ girth4 : num 1.11 1.19 1.09 1.25 1.11 1.08 1.11 1.16 1.05 1.17 ...
## $ ext4 : num 2.57 2.93 2.87 3.84 3.03 ...
## $ girth15 : num 3.58 3.75 3.93 3.94 3.6 3.51 3.98 3.62 4.09 4.06 ...
## $ weight15 : num 0.76 0.821 0.928 1.009 0.766 ...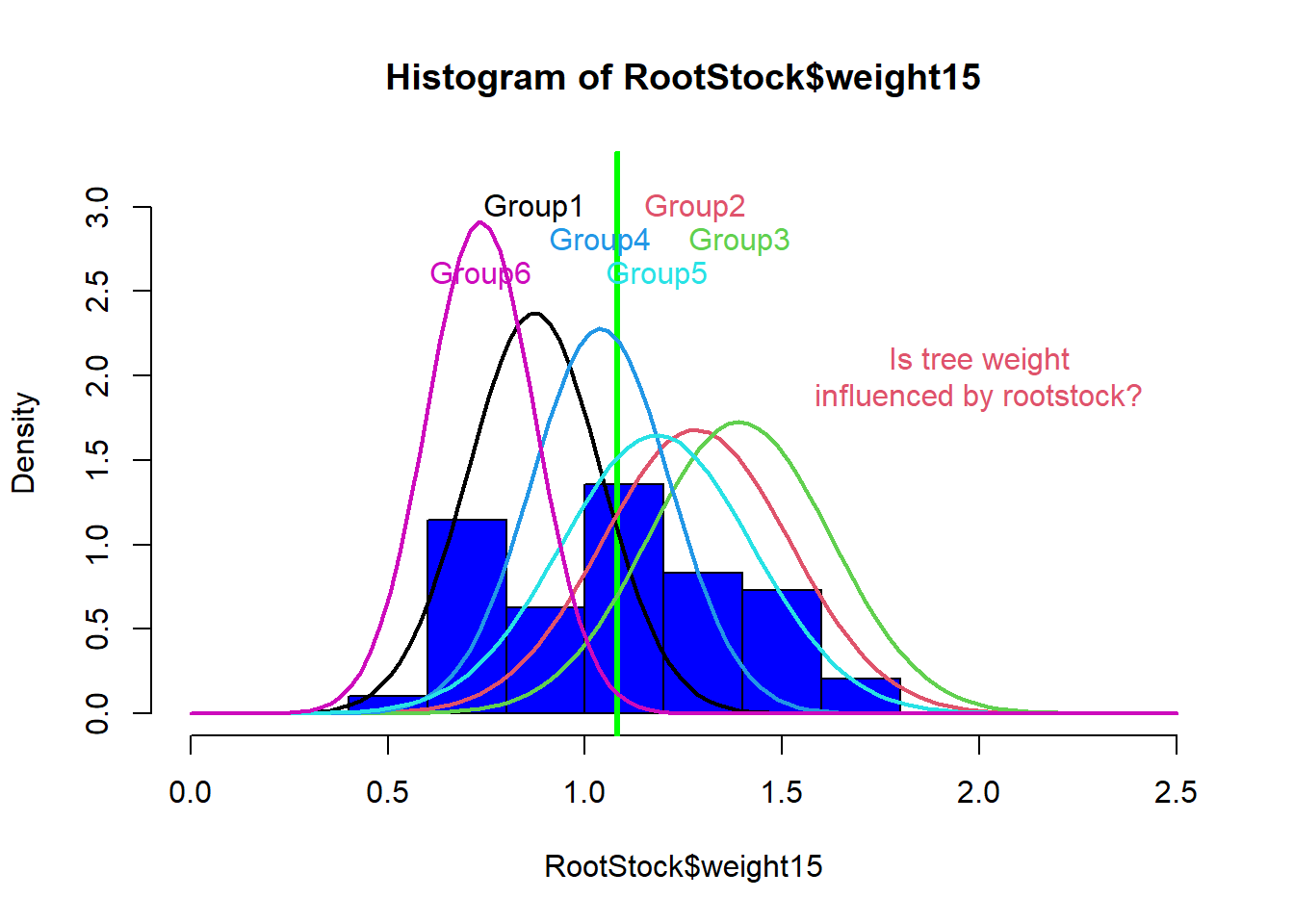
Figure 1: Histogram variable RootStock$weight15 illustrating bell curves for trees from each root stock.
- Examples of using one-way ANOVA in plant science:
- Does tree species affect the survival to fire disturbance?
- Does crop variety affect the final yield?
- Does the soil type affect root development?
- Does irrigation scheduling affect fruit weight?
- Examples of using two-way ANOVA in plant science:
- Do tree species and fire duration affect the survival to fire disturbance?
- Do variety and water regime affect crop yield?
- Do soil type and microbiome affect root development?
- Do irrigation scheduling and water quality affect fruit weight?
- Examples of using factorial ANOVA in plant science:
- Do tree species, tree age, and fire duration affect the survival to fire disturbance?
- Do variety, air temperature, and water regime affect crop yield?
- Do soil type, soil temperature, and microbiome affect root development?
- Do irrigation scheduling, irrigation type, and water quality affect fruit weight?
However, ANOVA can only assess one dependent variable at a time. This can be a problem because it can prevent the researcher from detecting effects and interaction terms that might actually exist.
MANOVA allows us to test multiple dependent variables at a time, providing a solution to this limitation from ANOVA. So, while in ANOVA we compare the means of more than two groups, in MANOVA we compare vectors of means between more than two groups (see Table 1).

Table 1: A table comparing differences between univariate and multivariate ANOVA.
- Advantages of using MANOVA are:
- Assess the influence of independent variables on the relationships between dependent variables;
- Limits the joint error rate, meaning that when performing multiple ANOVAs on each dependent variable, the joint probability of rejecting a true null hypothesis (Type I error) increases with each additional test. When using MANOVA the error rate equals the significance level.
Data assumptions
- As in ANOVA, data have to meet the following assumptions in MANOVA:
Independent observations: MANOVA assumes that each observation is randomly and independently sampled from the population. This assumption is met when the probability sampling method is used to collect data. Examples of probability sampling methods are: simple, stratified, clustered or systematic random sampling.
Multivariate normality for each group under comparison: this assumption is met when >20 observation per each factor*outcome variable are collected (Multivariate Central Limit Theorem). If the sample number is <20, we have to check the normality of the residuals of the data for each outcome variable. However, MANOVA is robust against slight violations of this assumption.
Equal variance and covariance matrices between groups: the most common way to check for this assumption is using Box’s M test. We usually use a significance level of 0.001 to determine whether or not the population covariance matrices are equal. If the p-value is higher than 0.001, the assumption is met. MANOVA is robust against slight variation of this assumption.
No multivariate outliers: calculate Mahalanobis distance can be for each observation, which represents the distance between two points in a multivariate space. Is the p-value associated with the Mahalanobis distance for one observation is less than 0.001, we declare that that observation is an outlier.
How does it work?
To understand how MANOVA assesses differences between groups, we will start by explaining how ANOVA works. ANOVA works by dividing the total deviation for each observation (observed value / overall mean) into the between groups deviation (group mean – overall mean) and the within groups deviation (also called error deviation, observed value – group mean). If these two are equal, the group means are equal. If they differ, the group means are not equal (see Figure 2).
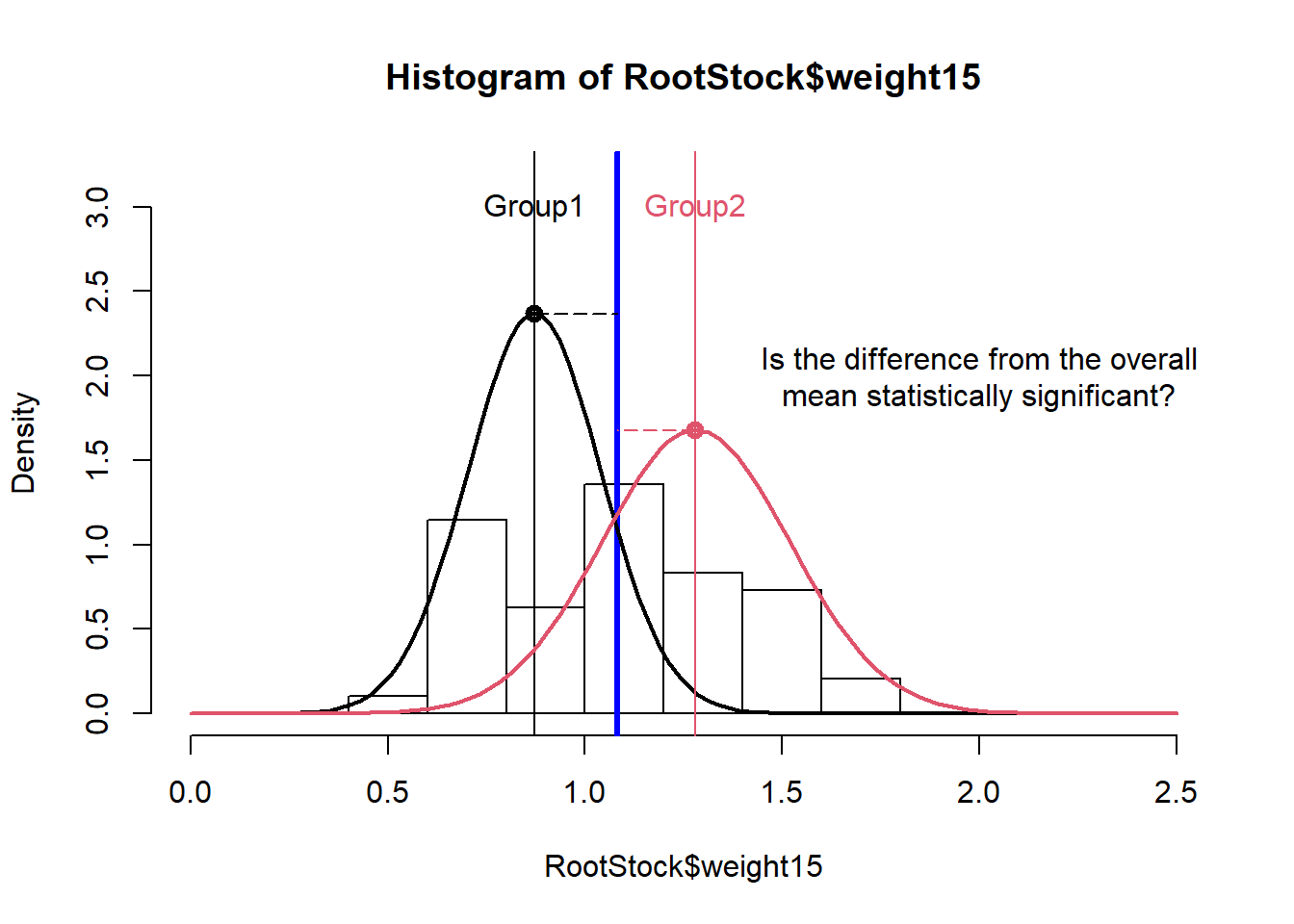
Figure 2: Histogram for tree weights illustrating mean differences for trees from root stock 1 and root stock 2.
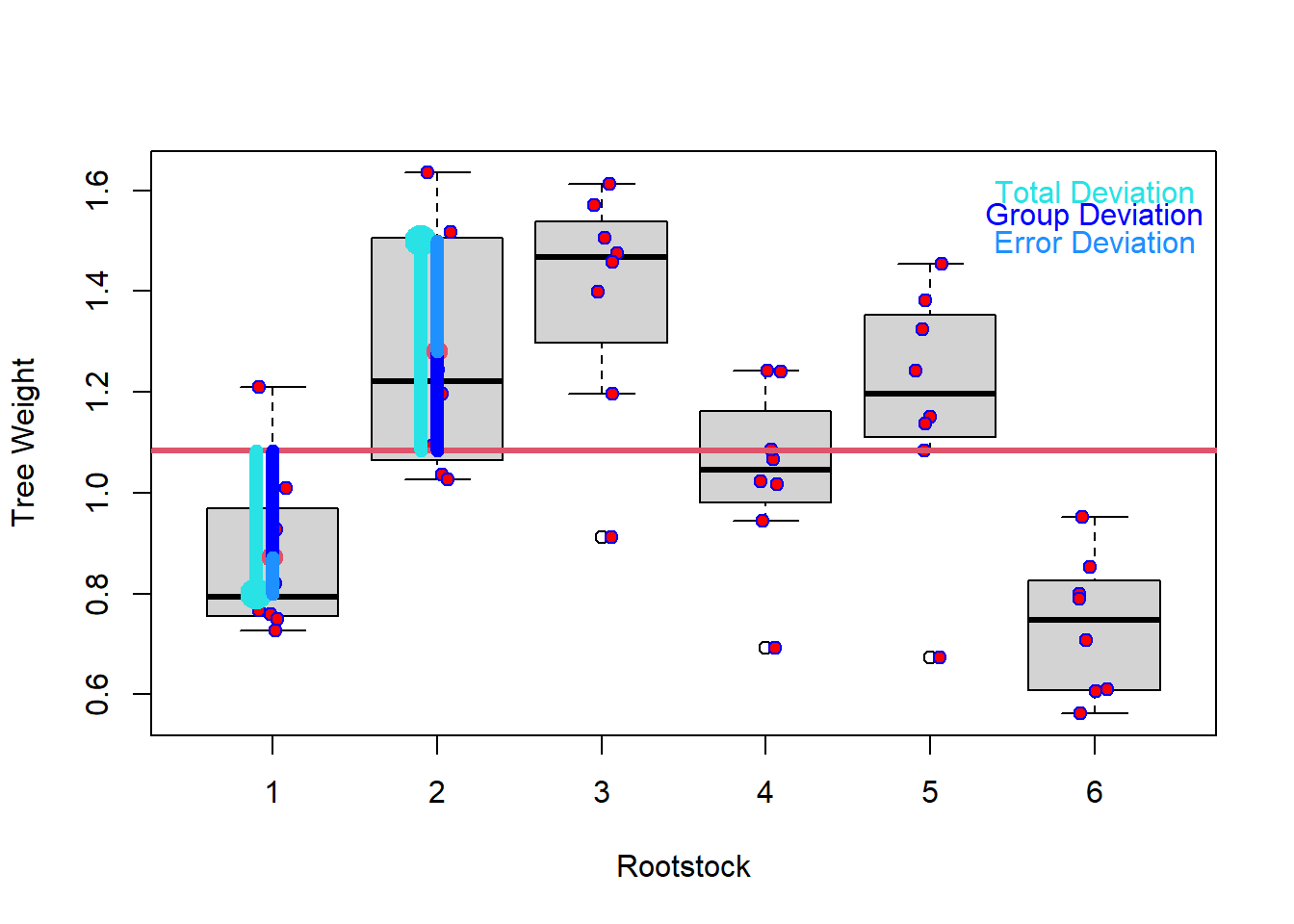
Figure 3: A boxplot showing total deviation, error deviation, and group deviation of tree weight.
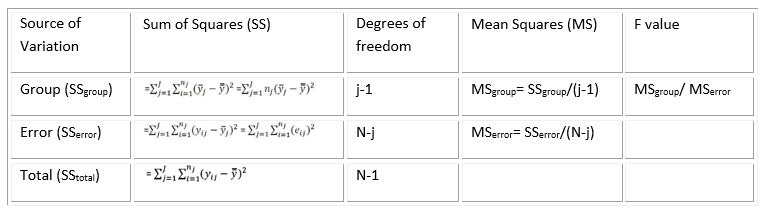
Table 2: A table showing calculations for an ANOVA table.
The F-value is calculated as variation between sample means and variation within samples. To calculate the p-value associate with the F-statistics, we use the F Distribution Calculator (F Distribution Calculator - Statology).
The F distribution has two parameters, which can be called “degrees of freedom 1 and 2” or “degrees of freedom numerator and denominator”. The F table (F Table - F distribution table) shows the F statistics correspondent to the cutoff threshold, below which we fail to reject the null hypothesis, and above which we can reject the null hypothesis.
The P-value associate with an F-value represents the area of the F distribution after the F-value. The higher the F-value, the more variance is explained by groups rather than by error deviation and the lower the p-value will be. If the p-value is lower than the cutoff threshold we set (alpha value), then we are able to reject the null hypothesis.
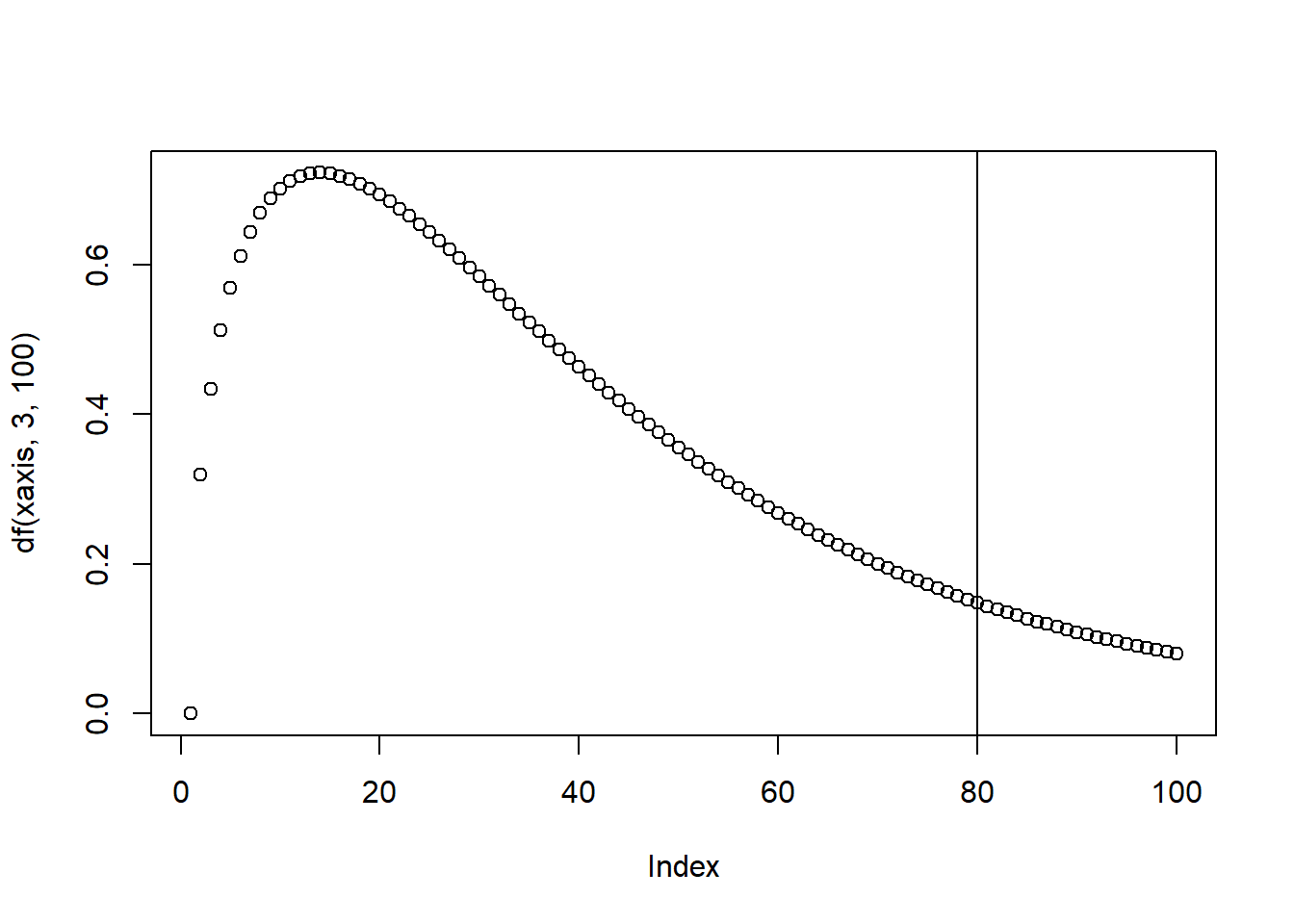
Figure 4: Illustration of the F-distribution.
ANOVA vs MANOVA - vectors!
A key difference between ANOVA and MANOVA tests is in how Sum of Squares are calculated (called Sum of Squares and Cross Product Matrices in MANOVA). In short, MANOVA uses a vector of means for the response variables to calculate the Sum of Squares calculations instead of a single mean of one response variable in an ANOVA test.
In MANOVA, the sum of squares is calculated by multiplying vectors of means (one mean per outcome variable), which implies that the Sum of Squares are matrices.
Total sum of squares in MANOVA is called T, or “Sum of Squares and Cross Product Matrices”.
SSgroup is called H, or “Hypothesis Sum of Squares and Cross Product Matrices”.
SSerror is called E, or “Error Sum of Squares and Cross Product Matrices”.
MANOVA test statistics
Because we are now working with matrices and not single values, we have to group response variables differently. We can do this by calculating 4 statistics which convert matrices into a scalar value.The significance of effects in MANOVA can be tested using the following test statistics:
Wilk’s lambda:
Wilks Lambda is the ratio of the determinant of the error sums of squares and cross products matrix E to the determinant of the total sum of squares and cross products matrix T= H + E. That is:
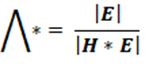
The null hypothesis of equality of treatment mean vectors is rejected if the ratio of generalized variance (Wilk’s lambda statistic) Λ* is too small (i.e. H is large relative to E). In short, This statistic represents the proportion of variation NOT explained by the model.
The Wilk’s lambda test is considered between liberal and conservative. Wilk’s lambda is often used as the default test statistic.
Pillai’s Trace:
Pillai’s trace is formulated by multiplying H by the inverse of the total sum of squares and cross products matrix T = H + E. Large value of the test statistics means H is relatively large to E, which leads to the rejection of the null hypothesis.
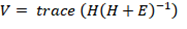
This test statistic is considered to be very robust and has a greater tolerance for non-normal data. Type II errors are more likely with Pillai’s Trace. When assumptions are violated and cannot be remedied or the experimental design is unbalanced, Pillai’s trace can be used.
Hotelling-Lawley trace:
The inverse of E is multiplied by H (sum of squares and sum of cross product matrices of treatments) and the trace of the resultant matrix is taken. For Larger H in comparison to E, means large value of the test statistics, large value of Hotelling-Lawley trace, leads to the rejection of the null hypothesis.
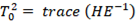
Hotelling-Lawley trace is analogous to an F-test and is equivalent to Hotelling’s T-squared divided by the differences between number of groups and sample size. It is considered a liberal test, as Type I errors are more likely. It is generally used in a controlled experimental setting where MANOVA assumptions are met very well.
Roy’s Largest Root:
H is multiplied by the inverse of E, and from the result and matrix the largest eigen value is obtained. Roy’s root will be large if H is substantially large compare to E, which leads to the rejection of the null hypothesis.
Also known as Roy’s largest eigenvalue, this statistic is most powerful in cases where one variable strongly distinguishes one group from all other groups. If all test statistics are significant, we can reject the null hypothesis and perform a post-hoc analysis to determine specific differences between groups.
MANOVA examples in R
One-Way MANOVA example in R
References
Data: Mona Farnisa. Hemp Phenotyping Study, 2021. University of Nevada, Reno.
Code: Tabachnick, Barbara, and Linda.S. Fidell. 2012. Using Multivarite Statistics. 6th ed. Pearson.
Packages
library(tidyverse)## -- Attaching packages --------------------------------------- tidyverse 1.3.1 --## v ggplot2 3.3.5 v purrr 0.3.4
## v tibble 3.1.3 v dplyr 1.0.7
## v tidyr 1.1.3 v stringr 1.4.0
## v readr 2.0.0 v forcats 0.5.1## -- Conflicts ------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()
## x dplyr::recode() masks car::recode()
## x purrr::some() masks car::some()library(tibble)
library(ggpubr)## Warning: package 'ggpubr' was built under R version 4.1.1library(rstatix)##
## Attaching package: 'rstatix'## The following object is masked from 'package:stats':
##
## filterlibrary(car)
library(broom)
library(mvtnorm)
library(dplyr)
library(tidyr)
library(purrr)
library(psych)## Warning: package 'psych' was built under R version 4.1.1##
## Attaching package: 'psych'## The following objects are masked from 'package:ggplot2':
##
## %+%, alpha## The following object is masked from 'package:car':
##
## logitlibrary(magrittr)##
## Attaching package: 'magrittr'## The following object is masked from 'package:purrr':
##
## set_names## The following object is masked from 'package:tidyr':
##
## extract# Load cleaned data
phenotype2.5 <- read.csv("phenotype_data.csv")
phenotype2.5$X <- NULL# Visualize dataset with boxplots
ggboxplot(phenotype2.5, x = "Variety", y = c("Height_cm", "True_Leaves"),
merge = TRUE, palette = "ggplot2")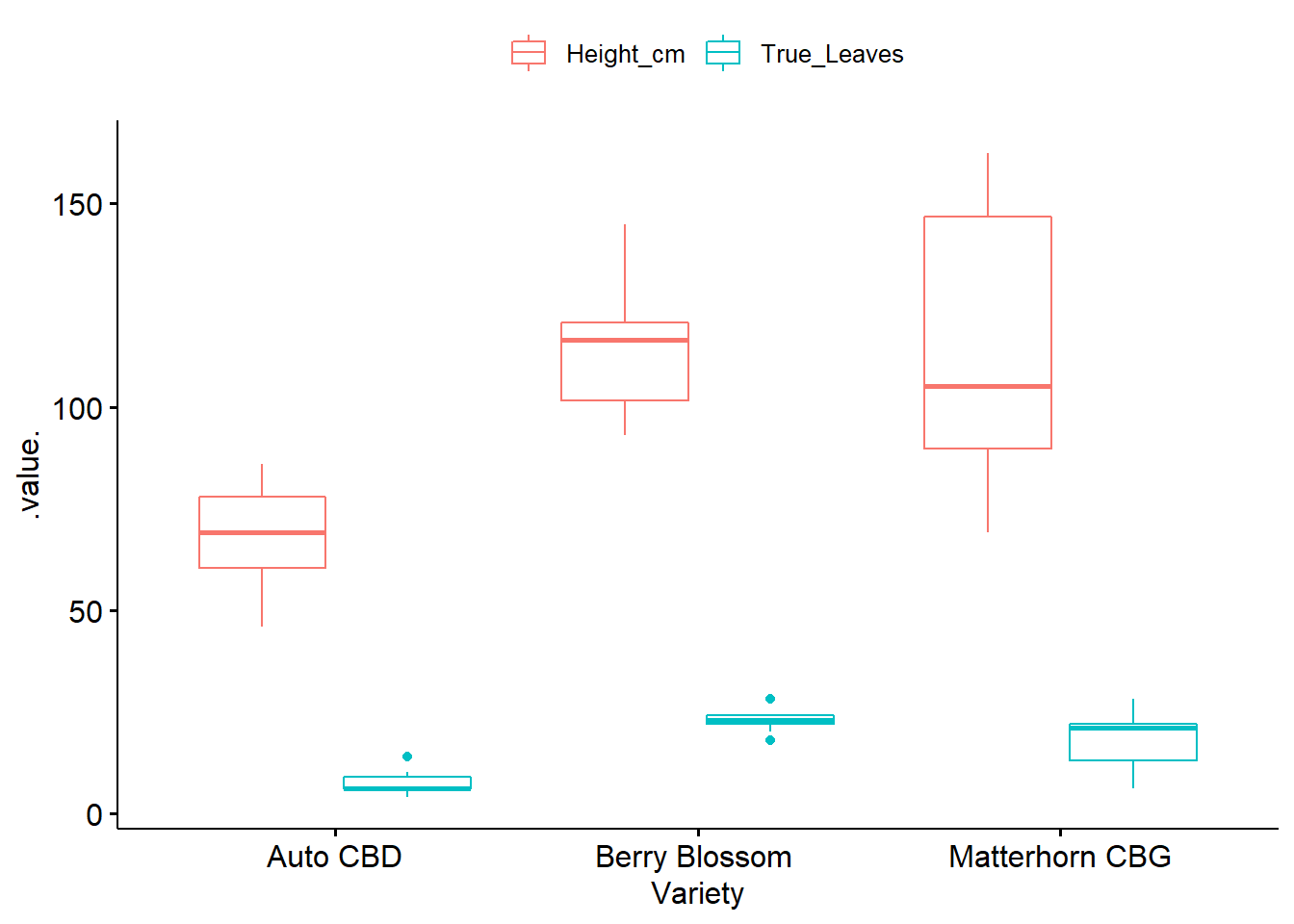
# Get Summary Statistics
phenotype2.5 %>%
group_by(Variety) %>%
get_summary_stats(Height_cm, True_Leaves, type = "mean_sd")## # A tibble: 6 x 5
## Variety variable n mean sd
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 "Auto CBD" Height_cm 10 68.1 12.1
## 2 "Auto CBD" True_Leaves 10 7.3 3.06
## 3 "Berry Blossom " Height_cm 10 114. 16.8
## 4 "Berry Blossom " True_Leaves 10 22.8 2.7
## 5 "Matterhorn CBG" Height_cm 10 113. 35.5
## 6 "Matterhorn CBG" True_Leaves 10 18.1 6.87Checking Assumptions
Adequate sample size: the n in each cell > the number of outcome variables.
Absense of univariate or multivariate outliers.
Multivariate normality.
Absence of multicollinearity.
Linearity between all outcome variables for each group.
Homogeneity of variances.
Homogeneity of variance-covariance matrices.
Check sample size assumption
# n in each group should be greater than number of outcome variables
phenotype2.5 %>%
group_by(Variety) %>%
summarise(N = n())## # A tibble: 3 x 2
## Variety N
## <chr> <int>
## 1 "Auto CBD" 10
## 2 "Berry Blossom " 10
## 3 "Matterhorn CBG" 10Identify univariate outliers
If outliers exist, they can be left in the data and compared in MANOVA result with and without outlier.
phenotype2.5 %>%
group_by(Variety) %>%
identify_outliers(Height_cm)## [1] Variety id Height_cm True_Leaves is.outlier is.extreme
## <0 rows> (or 0-length row.names)# no outliers!
phenotype2.5 %>%
group_by(Variety) %>%
identify_outliers(True_Leaves)## # A tibble: 3 x 6
## Variety id Height_cm True_Leaves is.outlier is.extreme
## <chr> <int> <dbl> <int> <lgl> <lgl>
## 1 "Auto CBD" 6 57 14 TRUE FALSE
## 2 "Berry Blossom " 12 118 28 TRUE FALSE
## 3 "Berry Blossom " 17 106. 18 TRUE FALSE# no outliers!Detect multivariate outliers with mahalnobis distance
Returns the squared Mahalanobis distance of all rows in x
phenotype2.5 %>%
group_by(Variety) %>%
mahalanobis_distance(-id) %>%
filter(is.outlier == TRUE) %>%
as.data.frame()## [1] id Height_cm True_Leaves mahal.dist is.outlier
## <0 rows> (or 0-length row.names)# no outliers!Univariate normality assumption with shapiro-wilks test
For sample sizer larger than 50, QQ-plots are recommended over Shapiro-Wilks, which becomes more sensitive to larger sample sizes
phenotype2.5 %>%
group_by(Variety) %>%
shapiro_test(Height_cm, True_Leaves) %>%
arrange(variable)## # A tibble: 6 x 4
## Variety variable statistic p
## <chr> <chr> <dbl> <dbl>
## 1 "Auto CBD" Height_cm 0.961 0.796
## 2 "Berry Blossom " Height_cm 0.951 0.684
## 3 "Matterhorn CBG" Height_cm 0.893 0.184
## 4 "Auto CBD" True_Leaves 0.807 0.0177
## 5 "Berry Blossom " True_Leaves 0.929 0.440
## 6 "Matterhorn CBG" True_Leaves 0.928 0.430# p-value > 0.05, so data is normally distributed, except for Auto CBD-True Leaves.
# However, MANOVA is fairly robust to deviations from normality so we will continueTest multivariate normality assumption
mshapiro_test() in rstatix package can be used to perform the Shapiro-Wilk test for multivariate normality.
# phenotype2.5 %>%
# select(Height_cm, True_Leaves) %>%
# mshapiro_test()
mshapiro_test(phenotype2.5[,2:3])## # A tibble: 1 x 2
## statistic p.value
## <dbl> <dbl>
## 1 0.969 0.499# p-value greater than 0.05, assumption met!Check multicolinearity between the variables
The dependent (outcome) variables cannot be too correlated to each other.
No correlation should be above r = 0.90 [Tabachnick and Fidell (2012)}.
Correlations that are too low can also be a problem
For more than 2 variables cor_mat() can be used
phenotype2.5 %>% cor_test(Height_cm, True_Leaves)## # A tibble: 1 x 8
## var1 var2 cor statistic p conf.low conf.high method
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 Height_cm True_Leaves 0.37 2.13 0.0421 0.0151 0.647 Pearson# Pearson correlation = 0.37
# p-value < 0.05, so no multicolinearity! Check linearity Assumption
Create a ggplot lm scatterplot by group to visually assess linearity between variables among groups
MANOVAs are best conducted when the dependent variables used in the analysis are highly negatively correlated and are also acceptable if the dependent variables are found to be correlated around .60, either positive or negative.
check.linearity <- ggplot(phenotype2.5, aes(x=Height_cm, y=True_Leaves, color=Variety))+
geom_point(size = 4)+
theme_classic()+
geom_smooth(method=lm, se=FALSE) +
ylab('True Leaves' ) +
xlab('Height (cm)') +
labs(color = 'Hemp Variety') #rename legend title
check.linearity## `geom_smooth()` using formula 'y ~ x'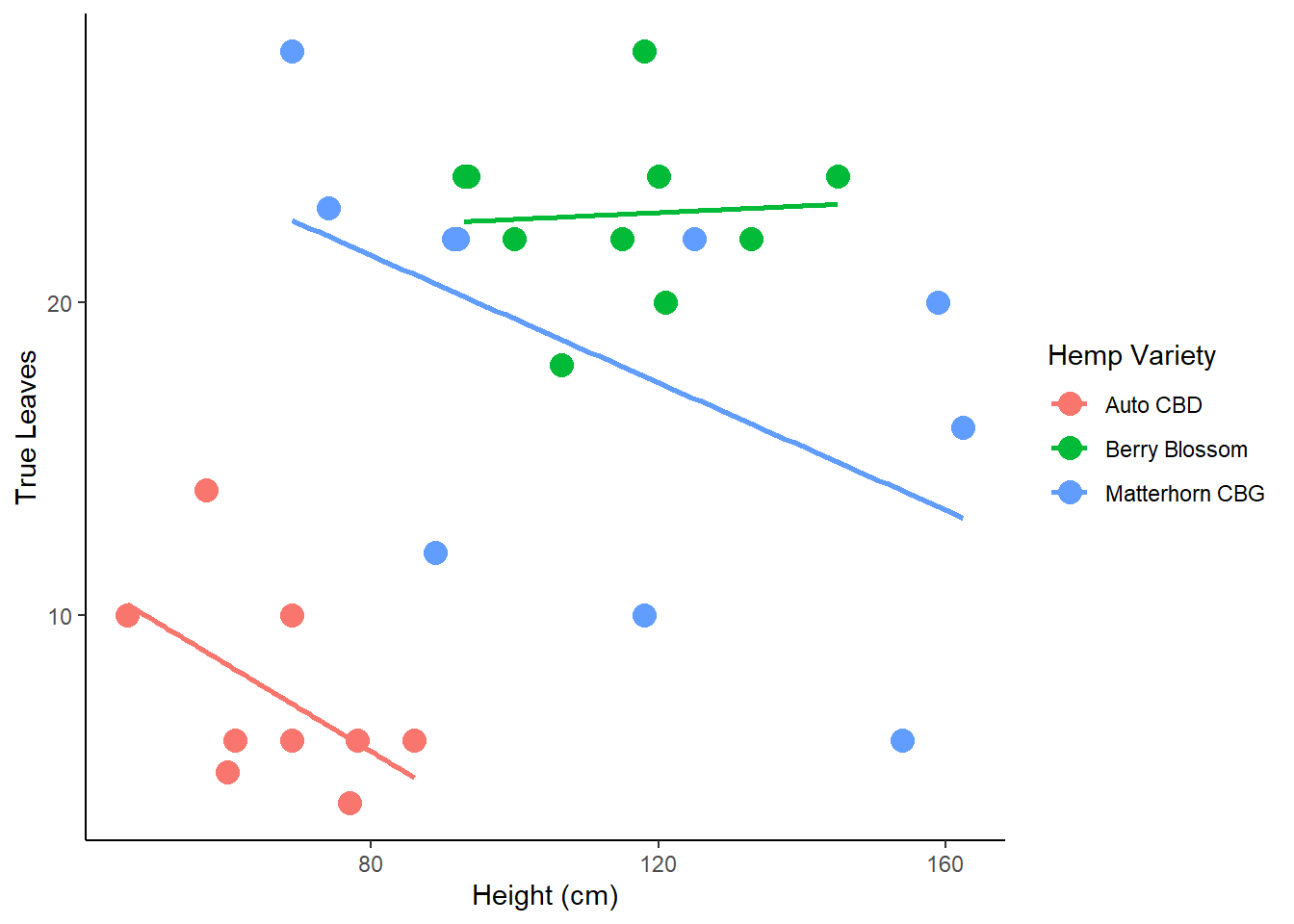
Check homogeneity of covariances with Box’s M-test in rstatix package
Box-M test is the equivalent of a multivariate homogeneity of variance.
This test is highly sensitive and significance for this test is determined at alpha = 0.001.
box_m(phenotype2.5[, c("Height_cm", "True_Leaves")], phenotype2.5$Variety)## # A tibble: 1 x 4
## statistic p.value parameter method
## <dbl> <dbl> <dbl> <chr>
## 1 19.0 0.00424 6 Box's M-test for Homogeneity of Covariance Matric~# p-value < 0.001, so assumption not metWith a balanced design of groups with similar n, violating homogeneity of variances-covariances matrices is not a problem and analysis can be continued!
However, an unbalanced design will present problems.
Check homogeneity of variance assumption with Levene’s test
The Levene’s test can be used to test the equality of variances between groups.
Non-significant values of Levene’s test indicate equal variance between groups.
phenotype2.5 %>%
gather(key = "variable", value = "value", Height_cm, True_Leaves) %>%
group_by(variable) %>%
levene_test(value ~ Variety)## Warning in leveneTest.default(y = y, group = group, ...): group coerced to
## factor.
## Warning in leveneTest.default(y = y, group = group, ...): group coerced to
## factor.## # A tibble: 2 x 5
## variable df1 df2 statistic p
## <chr> <int> <int> <dbl> <dbl>
## 1 Height_cm 2 27 7.97 0.00190
## 2 True_Leaves 2 27 3.17 0.0581# p-value < 0.05, so no homogeneity of variances!
# True Leaves p-value is 0.05, we will accept, but use Pillais test because it is robust against violations of assumptionsMANOVA
4 test statistics to use (Pillai, Wilks, Hotelling-Lawley, Roy)
Pillai test is more robust against violations of assumptions and recommended for unbalanced design.
Wilk’s lambda is default in R
model <- lm(cbind(Height_cm, True_Leaves) ~ Variety, phenotype2.5)
Manova(model, test.statistic = "Pillai")##
## Type II MANOVA Tests: Pillai test statistic
## Df test stat approx F num Df den Df Pr(>F)
## Variety 2 0.87714 10.546 4 54 2.186e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1# Statistically significant difference between Variety on the combined
# dependent variables (Height and True Leaves), F(4, 54) = 10.546, p < 0.0001.Post-hoc tests for statistically significant MANOVA
Do a one-way ANOVA for each dependent variable.
anova_test() when normality and homogeneity of variances is met
welch_anova_test() when homogeneity of variance is violated
kruskal_test() non-parametric alternative
grouped.data <- phenotype2.5 %>%
gather(key = "variable", value = "value", Height_cm, True_Leaves) %>%
group_by(variable)
grouped.data %>% welch_anova_test(value ~ Variety)## # A tibble: 2 x 8
## variable .y. n statistic DFn DFd p method
## * <chr> <chr> <int> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 Height_cm value 30 27.2 2 16.2 0.00000662 Welch ANOVA
## 2 True_Leaves value 30 69.9 2 16.7 0.00000000766 Welch ANOVA# Statistically significant univariate welch_anova difference in Height (F(2, 16.2) = 27.2, p < 0.0001)
# and True Leaves (F(2, 16.7) = 69.9, p < 0.0001 ) between hemp varieties. Compute multiple pairwise comparisons to determine which groups are different
If homogeneity of variance assumption is met use tukey_hsd()
If assumption of homogeneity of variance violated use Games-Howell post-hoc test.
pwc <- phenotype2.5 %>%
gather(key = "variables", value = "value", Height_cm, True_Leaves) %>%
group_by(variables) %>%
games_howell_test(value ~ Variety) %>%
select(-estimate, -conf.low, -conf.high) # Remove details
pwcpwc_alt_code <- phenotype2.5 %>%
gather(key = "variables", value = "value", Height_cm, True_Leaves) %>%
group_by(variables) %>%
games_howell_test(value ~ Variety) # %>%
# select(-estimate, -conf.low, -conf.high) # Remove details
pwc_alt_code$estimate <- NULL
pwc_alt_code$conf.low <- NULL
pwc_alt_code$conf.high <- NULL
pwc_alt_code## # A tibble: 6 x 6
## variables .y. group1 group2 p.adj p.adj.signif
## <chr> <chr> <chr> <chr> <dbl> <chr>
## 1 Height_cm value "Auto CBD" "Berry Blossom " 0.00000643 ****
## 2 Height_cm value "Auto CBD" "Matterhorn CBG" 0.007 **
## 3 Height_cm value "Berry Blossom " "Matterhorn CBG" 0.996 ns
## 4 True_Leaves value "Auto CBD" "Berry Blossom " 0.00000000172 ****
## 5 True_Leaves value "Auto CBD" "Matterhorn CBG" 0.002 **
## 6 True_Leaves value "Berry Blossom " "Matterhorn CBG" 0.152 nsResults
# Visualize Results: box plots with p-values
pwc_alt_code <- pwc_alt_code %>% add_xy_position(x = "Variety")
test.label <- create_test_label(
description = "MANOVA", statistic.text = quote(italic("F")),
statistic = 10.546, p= "<0.0001", parameter = "4,54",
type = "expression", detailed = TRUE
)
ggboxplot(
phenotype2.5, x = "Variety", y = c("Height_cm", "True_Leaves"),
merge = TRUE, palette = "ggplot2"
) +
stat_pvalue_manual(
pwc_alt_code, hide.ns = FALSE, tip.length = 0,
step.increase = 0.3, step.group.by = "variables",
color = "variables"
) +
labs(
subtitle = test.label,
caption = get_pwc_label(pwc_alt_code, type = "expression")
)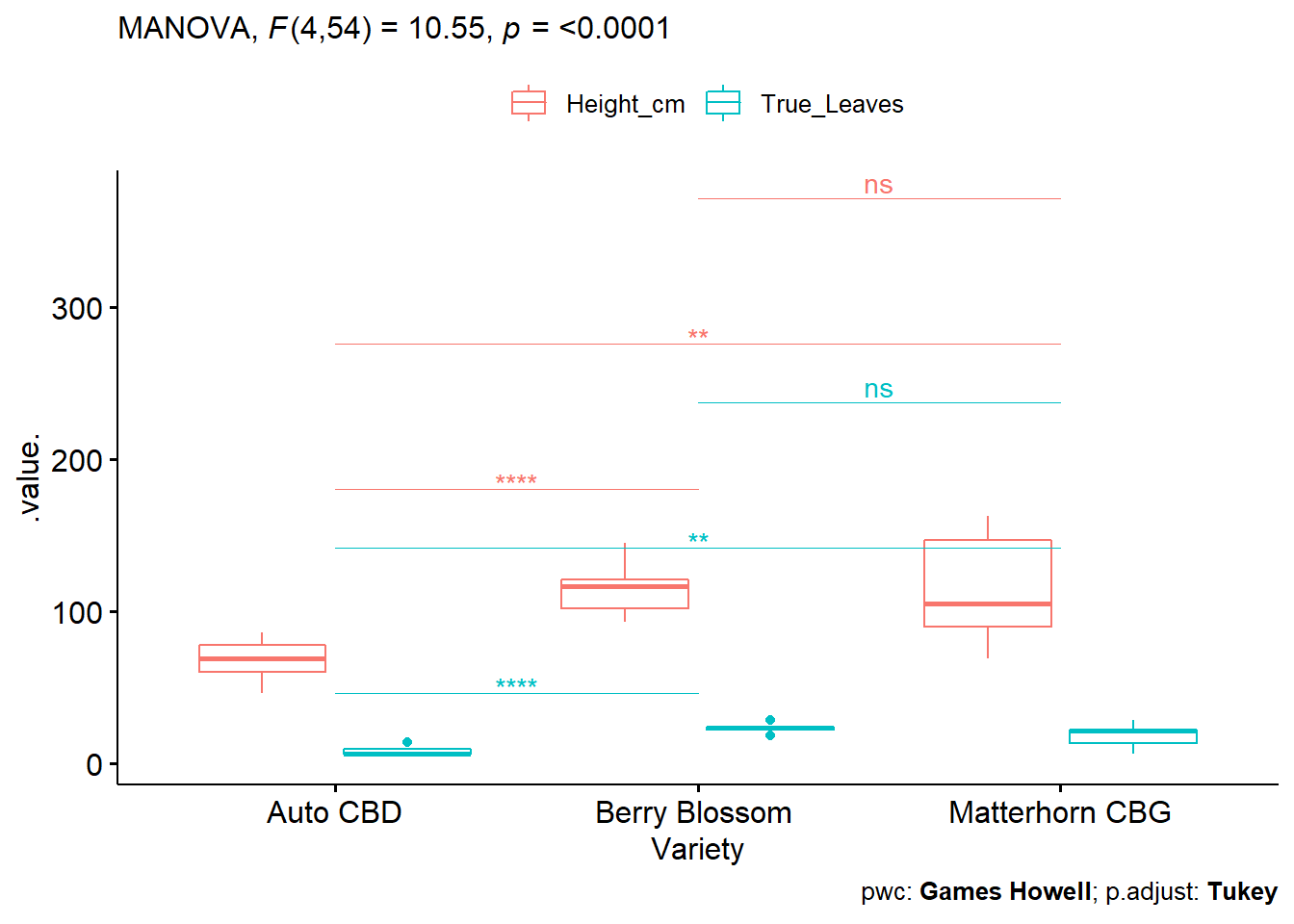
A one-way MANOVA to determine effect of 3 different hemp varieties (Auto CBD, Berry Blossom, Matterhorn CBG) on Height and True Leaves.
A statistically significant difference between varieties on the combined dependent variables F(4, 54) = 10.546, p < 0.0001.
Univariate ANOVAs, using a Bonferroni adjusted alpha level of 0.025, showed a statistically significant difference in Height (F(2, 16.2) = 27.2, p < 0.0001) and True Leaves (F(2, 16.7) = 69.9, p < 0.0001).
All pairwise comparisons between groups were significant except for Height and True Leaves between Berry Blossom and Matterhorn CBG using the Games-Howell pairwise comparison.
Factorial MANOVA example in R
A factorial MANOVA is used when a researcher wishes to investigate whether two or more grouping variables affect two or more outcome variables.
For this example, we will use the Soils dataset from the cars package. Details:
“Soil characteristics were measured on samples from three types of contours (Top, Slope, and Depression) and at four depths (0-10cm, 10-30cm, 30-60cm, and 60-90cm). The area was divided into 4 blocks, in a randomized block design.”
# load packages
library("car")
library("MASS")##
## Attaching package: 'MASS'## The following object is masked from 'package:rstatix':
##
## select## The following object is masked from 'package:dplyr':
##
## select#Load the data
soils <- Soils
# Make variables factors
Contour <- factor(soils$Contour)
Depth <- factor(soils$Depth)
head(soils)## Group Contour Depth Gp Block pH N Dens P Ca Mg K Na Conduc
## 1 1 Top 0-10 T0 1 5.40 0.188 0.92 215 16.35 7.65 0.72 1.14 1.09
## 2 1 Top 0-10 T0 2 5.65 0.165 1.04 208 12.25 5.15 0.71 0.94 1.35
## 3 1 Top 0-10 T0 3 5.14 0.260 0.95 300 13.02 5.68 0.68 0.60 1.41
## 4 1 Top 0-10 T0 4 5.14 0.169 1.10 248 11.92 7.88 1.09 1.01 1.64
## 5 2 Top 10-30 T1 1 5.14 0.164 1.12 174 14.17 8.12 0.70 2.17 1.85
## 6 2 Top 10-30 T1 2 5.10 0.094 1.22 129 8.55 6.92 0.81 2.67 3.18We will focus on three outcome variables (pH, Density, Conductivity) and two independent variables (contour (top, slope, and depression), depth (0-10 cm, 10-30 cm, 30-60cm, and 60-90 cm)). And test the following:
Null hypotheses being tested:
The joint mean of the outcome variables (pH, Density, and COnductivity) ARE NOT significantly different among the categories of the grouping variables.
The joint mean of the outcome variables (pH, Density, and Conductivity) ARE NOT significantly different for combinations of the contrours*Depth interaction.
Note: Assumptions should always be verified as was done in the one-way MANOVA example. For brevity, this will be skipped here.
Create a model and determine Sum of Squares type:
Three types of sum of squares
Type I SS: Also called Sequential Sum of Squares, will assign variation in sequential order to grouping variables.
Type II SS: Here, variation assigned to each variable takes into account the other grouping variable(s). Type II is used when there is no significant interaction term.
Type III SS: Also called the partial sums of squares, like Type II, order of the variables is not considered. It is different from Type II in that it is used when there is a significant interaction term.
# Create a model, have to bind the 3 outcome variables using cbind().
soils.mod <- lm(cbind(pH, Dens, Conduc) ~ Contour + Depth + Contour*Depth -1, data = soils) # Note: -1 removes the intercept effect
summary(soils.mod)## Response pH :
##
## Call:
## lm(formula = pH ~ Contour + Depth + Contour * Depth - 1, data = soils)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.7125 -0.1775 -0.0125 0.1681 1.3875
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## ContourDepression 5.3525 0.1951 27.438 < 2e-16 ***
## ContourSlope 5.5075 0.1951 28.233 < 2e-16 ***
## ContourTop 5.3325 0.1951 27.336 < 2e-16 ***
## Depth10-30 -0.4725 0.2759 -1.713 0.095366 .
## Depth30-60 -0.9900 0.2759 -3.589 0.000982 ***
## Depth60-90 -1.1800 0.2759 -4.277 0.000133 ***
## ContourSlope:Depth10-30 0.2475 0.3901 0.634 0.529848
## ContourTop:Depth10-30 -0.0100 0.3901 -0.026 0.979693
## ContourSlope:Depth30-60 -0.2500 0.3901 -0.641 0.525723
## ContourTop:Depth30-60 -0.1375 0.3901 -0.352 0.726571
## ContourSlope:Depth60-90 -0.4000 0.3901 -1.025 0.312085
## ContourTop:Depth60-90 -0.2600 0.3901 -0.666 0.509396
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.3901 on 36 degrees of freedom
## Multiple R-squared: 0.9949, Adjusted R-squared: 0.9932
## F-statistic: 581.6 on 12 and 36 DF, p-value: < 2.2e-16
##
##
## Response Dens :
##
## Call:
## lm(formula = Dens ~ Contour + Depth + Contour * Depth - 1, data = soils)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.25250 -0.07687 0.01750 0.08000 0.21750
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## ContourDepression 0.97750 0.06148 15.899 < 2e-16 ***
## ContourSlope 1.05000 0.06148 17.079 < 2e-16 ***
## ContourTop 1.00250 0.06148 16.306 < 2e-16 ***
## Depth10-30 0.38000 0.08695 4.370 0.000101 ***
## Depth30-60 0.55750 0.08695 6.412 1.96e-07 ***
## Depth60-90 0.52500 0.08695 6.038 6.18e-07 ***
## ContourSlope:Depth10-30 -0.08250 0.12296 -0.671 0.506539
## ContourTop:Depth10-30 -0.05000 0.12296 -0.407 0.686685
## ContourSlope:Depth30-60 -0.09750 0.12296 -0.793 0.433012
## ContourTop:Depth30-60 -0.23750 0.12296 -1.932 0.061323 .
## ContourSlope:Depth60-90 -0.15250 0.12296 -1.240 0.222914
## ContourTop:Depth60-90 -0.09750 0.12296 -0.793 0.433012
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.123 on 36 degrees of freedom
## Multiple R-squared: 0.9936, Adjusted R-squared: 0.9915
## F-statistic: 467.6 on 12 and 36 DF, p-value: < 2.2e-16
##
##
## Response Conduc :
##
## Call:
## lm(formula = Conduc ~ Contour + Depth + Contour * Depth - 1,
## data = soils)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.9275 -0.7400 -0.0463 0.7981 3.1900
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## ContourDepression 1.4725 0.6127 2.403 0.02153 *
## ContourSlope 2.0500 0.6127 3.346 0.00193 **
## ContourTop 1.3725 0.6127 2.240 0.03136 *
## Depth10-30 4.0075 0.8665 4.625 4.70e-05 ***
## Depth30-60 7.9200 0.8665 9.140 6.49e-11 ***
## Depth60-90 9.9650 0.8665 11.500 1.31e-13 ***
## ContourSlope:Depth10-30 -1.1475 1.2255 -0.936 0.35532
## ContourTop:Depth10-30 -1.7975 1.2255 -1.467 0.15111
## ContourSlope:Depth30-60 -1.0450 1.2255 -0.853 0.39944
## ContourTop:Depth30-60 -1.8525 1.2255 -1.512 0.13935
## ContourSlope:Depth60-90 -0.0450 1.2255 -0.037 0.97091
## ContourTop:Depth60-90 -0.3075 1.2255 -0.251 0.80330
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.225 on 36 degrees of freedom
## Multiple R-squared: 0.9809, Adjusted R-squared: 0.9745
## F-statistic: 154.1 on 12 and 36 DF, p-value: < 2.2e-16The summary of this model shows contour and depth have significant effects on our outcome variables, but interaction terms are not (all greater than 0.05). When running a MANOVA, the type of Sum of Squares we wish to estimate must be specified.
In our case, so we can use the type II sum of squares to test our null hypotheses as we do not have a significant interaction term.
As discussed previously, Wilk’s lambda is considered between liberal and conservative and often used as the default test statistic. Because there is no obvious reason to use another test statistic at this point, let’s use Wilk’s lambda.
Note: This article gives a great summary of ANOVA Sum of Squares types.
Run the MANOVA
# Note: Manova() is brought to you by the car package
Manova(soils.mod, multivariate=T, type= c("II"), test=("Wilks"))##
## Type II MANOVA Tests: Wilks test statistic
## Df test stat approx F num Df den Df Pr(>F)
## Contour 3 0.00939 53.497 9 82.898 <2e-16 ***
## Depth 3 0.03164 28.855 9 82.898 <2e-16 ***
## Contour:Depth 6 0.71510 0.676 18 96.652 0.8269
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1# Manova(soils.mod, multivariate=T, type= c("II"), test=("Pillai"))
# Manova(soils.mod, multivariate=T, type= c("II"), test=("Hotelling-Lawley"))
# Manova(soils.mod, multivariate=T, type= c("II"), test=("Roy"))
### If we did have an interaction term we would use type III
manova(soils.mod, multivariate=T, type= c("III"), test=("wilks"))## Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
## extra arguments 'multivariate', 'type', 'test' will be disregarded## Call:
## manova(soils.mod, multivariate = T, type = c("III"), test = ("wilks"))
##
## Terms:
## Contour Depth Contour:Depth Residuals
## pH 1046.8077 14.9590 0.5159 5.4798
## Dens 83.1553 1.5898 0.0884 0.5443
## Conduc 2096.4990 674.4830 5.8732 54.0631
## Deg. of Freedom 3 3 6 36
##
## Residual standard errors: 0.3901487 0.1229612 1.22546
## Estimated effects may be unbalanced# manova(soils.mod, multivariate=T, type= c("III"), test=("Pillai"))
# manova(soils.mod, multivariate=T, type= c("III"), test=("Hotelling-Lawley"))
# manova(soils.mod, multivariate=T, type= c("III"), test=("Roy"))Each test statistic shows the interaction between contour and depth are not significant. Can reject our first null, but not the second one.
Partial Eta-Squared Values for a factorial MANOVA
Partial eta-squared explains the portion of total variation from a specific grouping variable excluding all other grouping variables. This is commonly used as a measure of effect size.
In our example, each group variable(Contour and Depth) will have their own partial eta-squared values.
library("heplots")
etasq(Anova(soils.mod),anova=TRUE)##
## Type II MANOVA Tests: Pillai test statistic
## eta^2 Df test stat approx F num Df den Df Pr(>F)
## Contour 0.39218 3 1.17654 7.7427 9 108 1.010e-08 ***
## Depth 0.45907 3 1.37721 10.1840 9 108 3.154e-11 ***
## Contour:Depth 0.10488 6 0.31463 0.7030 18 108 0.8015
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1etasq(soils.mod,test="Wilks") # Using Wilks to be consistent with above## eta^2
## Contour 0.7890322
## Depth 0.6837136
## Contour:Depth 0.1057565# etasq(soils.mod,test="Hotelling")
# etasq(soils.mod,test="Roy")
# etasq(soils.mod,test="Pillai")We can say that 78.9% of the variance of our outcome variables is due to the differences in the contour of the soil, and 68% due to the depth.
Other variations of ANOVA
ANCOVA/MANCOVA - Analysis of Covariance - an extension of ANOVA which can be used to control for covariates, or to study combinations of categorical and continuous variables.
Repeated Measures ANOVA - useful when using pre- and post-treatment data, or differences over two or more time periods.
Mixed-Model ANOVA (within-between ANOVA) - Used when examining differences in a response between/among treatments and over time (pre and post treatment, for example)
Bayesian ANOVA - Instead of traditional hypothesis testing in which an F statistic and p-value are used to reject/not reject a null hypothesis, a Bayesian ANOVA can provide support for an alternative hypothesis.
Resources we found helpful
Bobbitt, Z. (2021, August 3). The Complete Guide: How To Check Manova Assumptions. Statology. Retrieved November 14, 2021, from https://www.statology.org/manova-assumptions/.
Buttigieg PL, Ramette A (2014) A Guide to Statistical Analysis in Microbial Ecology: a community-focused, living review of multivariate data analyses. FEMS Microbiol Ecol. 90: 543–550.
Cleophas T.J., Zwinderman A.H. (2018) Bayesian Analysis of Variance (Anova). In: Modern Bayesian Statistics in Clinical Research. Springer, Cham. https://doi-org.unr.idm.oclc.org/10.1007/978-3-319-92747-3_8
Korstanje, J. (2019, November 29). ANOVA’s three types of estimating sums of squares: Don’t make the wrong choice! Medium. Retrieved November 14, 2021, from https://towardsdatascience.com/anovas-three-types-of-estimating-sums-of-squares-don-t-make-the-wrong-choice-91107c77a27a.
RenaissanceWoman. (2018, February 14). Multivariate Statistical Analysis Part 2: MANOVA (with R Demonstration) [Video]. YouTube. https://www.youtube.com/watch?v=SK6Tg3na3mo
Sarhad Journal of Agriculture, Vol.37, Iss. 4, Pages 1250-1259
Wang, Yifan. (2016). Using Multivariate Analysis for Pharmaceutical Drug Product Development. 10.13140/RG.2.2.23379.78881.