Parameter estimation
NRES 470/670
Spring 2026
Parameter estimation for wildlife population models!
We have now gone through the basic mechanics of population modeling. But we have barely discussed where the parameter estimates come from!
This is the focus of the current lecture- and much of NRES 488!
Data requirements
Scalar models (no age structure)
- Initial abundance (\(N_0\))
- Mean population growth rate (\(r\) or \(r_{max}\))
- Variation in population growth rate (standard deviation for a normal distribution representing environmental stochasticity)
- Carrying capacity of the population (\(K\); equilibrium abundance of logistic model)
Stage-structured (life history) models
- Initial abundance (\(\mathbf{N_0}\)) (vector of initial abundances for all stages)
- Stage-specific vital rates (fecundity, survival; fill in a transition matrix)
- Temporal variation in specific vital rates (environmental stochasticity)
- Density-dependence of vital rates (e.g., how fecundity decreases as
population gets more crowded)
- Which vital rates are density-dependent?
Metapopulation (spatial) models
- Spatial distributions of suitable habitat patches (define patches)
- Spatial variation in vital rates (e.g., variation in habitat quality among different patches)
- Correlation in environmental stochasticity among patches
- Dispersal rates among habitat patches
- Habitat requirements of different life stages
- For “classical” metapopulation models: rates of colonization and extinction in habitat patches
Data sources!
Census data!
Census data is ultimately what we all wish we had! It means we follow a population over time, and we know exactly how many individuals of each stage are in the population each year. We have perfect detection!
In this case, computing survival and fecundity (and variation in these parameters, and density-dependence) is relatively straightforward!
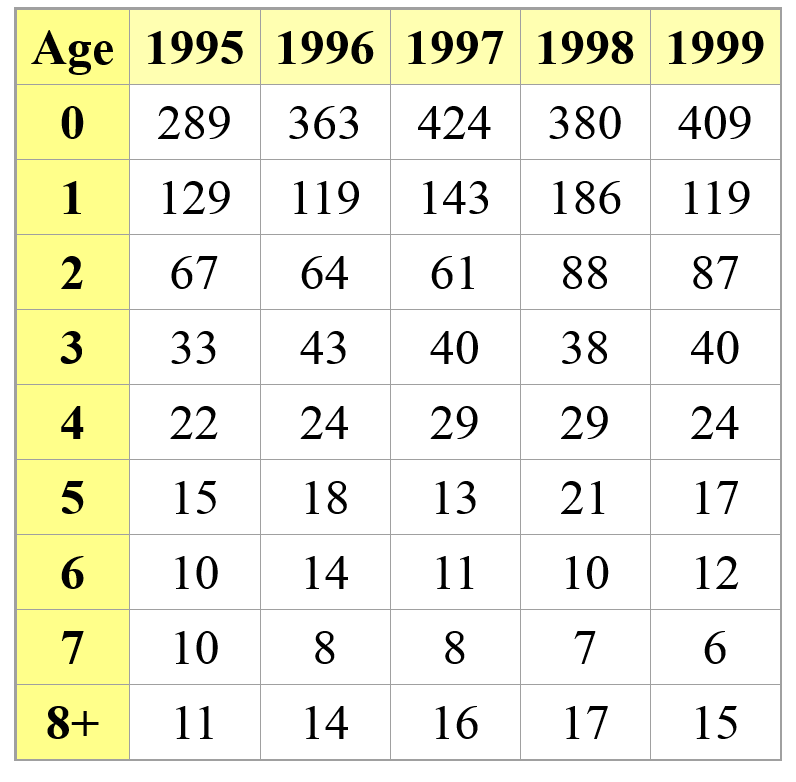
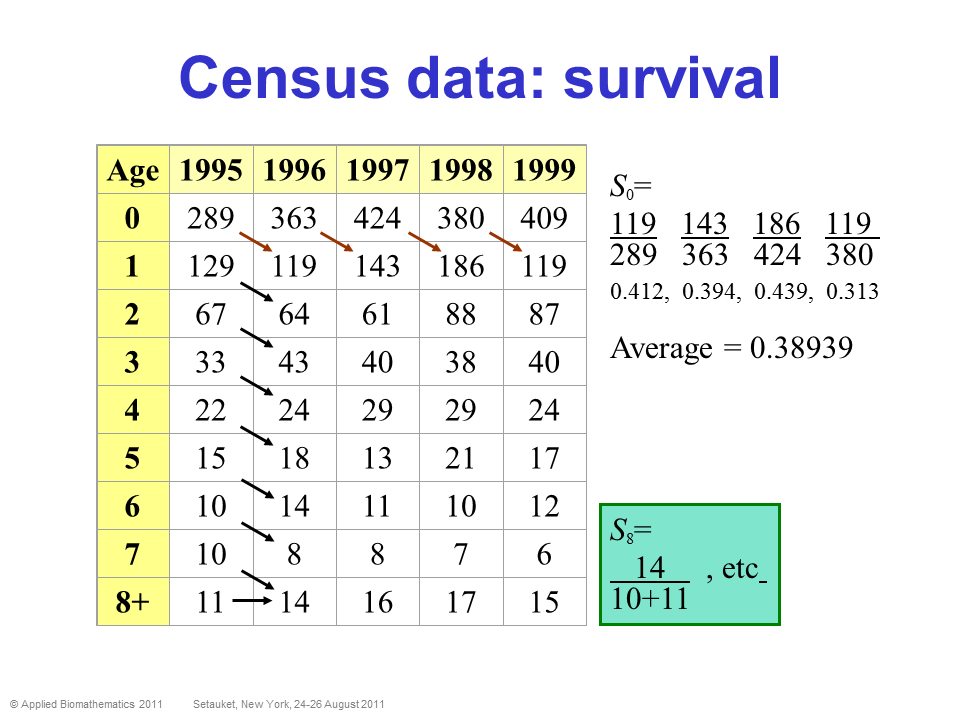

PROS - Can estimate survival and fecundity, env. stochasticity, density dependence- pretty much everything we want for a population model!
CONS - Very rarely available for wild populations!! - Ignores imperfect detection (assumes no observation errors), which is almost always not realistic (for wild populations).
What if there’s “no data”?
Recall the “Stone Soup” analogy! - even when you think there’s no data, there probably is more than there initially appears!
- Use algebra to construct a full age-structured transition matrix
from available information
- E.g., we are missing information on hatchling survival. We only
know:
- Juvenile and adult survival rates
- Nesting success
- Population growth (lambda) is 1.09
- Now we can solve for the unknown – hatchling survival!
- For an example of this, see Congdon et al 1993
- Juvenile and adult survival rates
- E.g., we are missing information on hatchling survival. We only
know:
- Simplify! (Models are always simplified representations of reality)
- Ignore age structure? (i.e., use scalar model)
- Ignore density-dependence?
- Ignore trophic interactions (we usually make this simplification
anyway!)
- Ignore abundance entirely (e.g., use classical metapopulation
model)
- Ignore age structure? (i.e., use scalar model)
- Conservative strategies (use worst case scenario)!
- Density-independent model is conservative, so if you don’t have data
on D-D, then maybe just ignore it!
- With parameter uncertainty, use the worst case scenario
- Under decline trends, use the worst case scenario
- Density-independent model is conservative, so if you don’t have data
on D-D, then maybe just ignore it!
- Use data from similar species!
- E.g., tamarin species have similar life histories, so use data on golden lion tamarins to model golden-headed lion tamarins.
- Expert Opinion
- See below…
- National Databases
- See links on Final projects page
- Allometries
- e.g., Fenchel’s allometry
- This type of thinking (looking for broad patterns across species) is often called “Macroecology”
Aside- is expert opinion okay to use???
- Not ideal, because it is hard or impossible to validate, and hard to document, but …
- That is often the default in practice
- And it is better to use it than to do nothing
- And it is better to document that expert opinion was used than to proceed with conservation planning in the absence of stating sources and assumptions
- It is a starting point (and sometimes the best we have)
Capture-mark-recapture (CMR)
PROS - Can estimate abundance, survival, variation in survival, lambda, recruitment, dispersal rates. - Probably the most widely used source of data for population models (especially if you consider that telemetry data is a special class of capture-mark-recapture data!
CONS - Cost: mounting a proper CMR study can be very costly, and require many years of data. - Estimating landscape-scale movements can require an even more costly and time-consuming study. - Emigration and survival can be difficult to tease apart in many cases. - The analytical techniques can be difficult to master
Statistics and wildlife population ecology
Capture-recapture analyses are derived from central principles of probability and statistics.
PVA Parameters estimable from CMR data
- Survival rate (possibly age or size structured)
- Fecundity (entry of new individuals in the population)
- Recruitment (entry of new individuals into the adult
population)
- Abundance
- Lambda (finite rate of growth)
- Environmental influences on survival rates and fecundity
- Temporal process variance (env. stochasticity)
- Dispersal rates
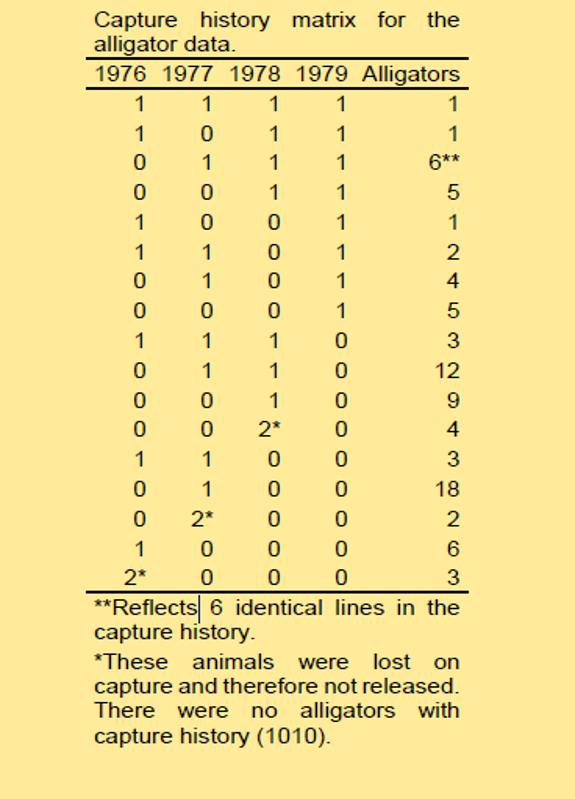
The data needed for CMR analysis: capture histories
Consider a project designed to monitor a population of alligators. These alligators were monitored for four years, from 1976 to 1979.
Each row in the following table represents a unique possible history of captures:
A “1” indicates that an animal was successfully captured in a given year, and subsequently released.
A “0” indicates that an animal was not captured in a given year.
A “2” indicates that an animal was successfully captured in a given year but was not released back into the population (probably died due to handling or capture).
Two main types of CMR analyses
Closed population models
We assume that the population is closed (no BIDE processes!). That is, abundance does not change! We attempt to estimate abundance!
- No mortality
- No births
- No immigration
- No emigration
- All individuals are observable (but not necessarily observed…)

Parameters estimated:
- Abundance
M = the number of individuals marked in the first sample
C = total number of individuals captured in 2nd sample
R = number of individuals in 2nd sample that are marked
We can use the following formula to estimate abundance (the Lincoln-Peterson estimator):
\[\hat N = \frac{M \times C}{R}\]
Open population models
We assume that the population is open to one or more of the BIDE processes. That is, abundance CAN change! We attempt to estimate the processes driving changes in abundance (often, survival rates)
- Populations open to birth, death, and possibly even migration (abundance can change during the study).
- Enables estimation of the drivers of population dynamics over extended time periods
- Often of great interest to ecologists and managers.
Key assumptions of the CJS model
- All individuals in population are equally detectable at each
sampling occasion (each capture session represents a totally random
sample from the population)
- Marks are not lost or missed by surveyors
- All emigration is permanent (equivalent to a mortality)
Program MARK
MARK is a numerical maximum-likelihood engine designed for mark-recapture analysis. You input a capture history dataset and MARK will output results such as survival rate and capture probability!!
Example of an open-population mark-recapture analysis!
Let’s run through a CJS analysis in R! To follow along, please save this script and load it up in Rstudio.
NOTE: this analysis includes both males and females (unlike the example in Lab 7), so the results will look somewhat different!

The European dipper data is THE classic example of a CMR dataset. Let’s look at it!
# Cormack-Jolly-Seber (CJS) model in R --------------------------
library(marked) # install the 'marked' package if you haven't already done this!## Loading required package: lme4## Loading required package: Matrix## Loading required package: parallel## This is marked 1.2.8data("dipper")
head(dipper,10)## ch sex
## 1 0000001 Female
## 2 0000001 Female
## 3 0000001 Female
## 4 0000001 Female
## 5 0000001 Female
## 6 0000001 Female
## 7 0000001 Female
## 8 0000001 Female
## 9 0000001 Female
## 10 0000001 FemaleHere we use the “marked” package in R (instead of MARK) to do the ML parameter estimation!
# load data! ----------------------------
data(dipper)
# Process data -------------------------------
dipper.proc=process.data(dipper,model="cjs",begin.time=1) # Helper function- process the data for CJS model## 255 capture histories collapsed into 53dipper.ddl=make.design.data(dipper.proc) # another helper function- process data!
# Fit models
# fit time-varying cjs model
capture.output(suppressMessages( # note: this is just to suppress messages to avoid cluttering the website...
mod.Phit.pt <- crm(dipper.proc,dipper.ddl,model.parameters=list(Phi=list(formula=~time),p=list(formula=~time)),method="Nelder-Mead",hessian = T)
),file="temp.txt")
mod.Phit.pt # print out model##
## crm Model Summary
##
## Npar : 12
## -2lnL: 657.0644
## AIC : 681.0644
##
## Beta
## Estimate se lcl ucl
## Phi.(Intercept) 0.75646636 0.6570806 -0.5314115 2.0443443
## Phi.time2 -0.99255899 0.7541098 -2.4706141 0.4854961
## Phi.time3 -0.84151202 0.6991671 -2.2118796 0.5288556
## Phi.time4 -0.22522075 0.7051952 -1.6074033 1.1569618
## Phi.time5 -0.36893542 0.6974964 -1.7360283 0.9981575
## Phi.time6 0.10115137 1.5063612 -2.8513166 3.0536194
## p.(Intercept) 1.00571207 0.8006507 -0.5635632 2.5749874
## p.time3 1.49463757 1.3119502 -1.0767848 4.0660600
## p.time4 1.37853596 1.0927335 -0.7632218 3.5202937
## p.time5 1.12053506 0.9914942 -0.8227935 3.0638636
## p.time6 1.57229762 1.0715539 -0.5279481 3.6725434
## p.time7 0.07823848 1.7821196 -3.4147158 3.5711928mod.Phit.pt$results$AIC # extract AIC## [1] 681.0644# fit time-invariant cjs model
capture.output(suppressMessages(
mod.Phidot.pdot <- crm(dipper.proc,dipper.ddl,model.parameters = list(Phi=list(formula=~1),p=list(formula=~1)),method="Nelder-Mead",hessian = TRUE)
),file="temp.txt")
mod.Phidot.pdot##
## crm Model Summary
##
## Npar : 2
## -2lnL: 666.8377
## AIC : 670.8377
##
## Beta
## Estimate se lcl ucl
## Phi.(Intercept) 0.2422903 0.1020150 0.04234102 0.4422397
## p.(Intercept) 2.2261889 0.3251153 1.58896300 2.8634148mod.Phidot.pdot$results$AIC## [1] 670.8377# fit sex-dependent cjs model
capture.output(suppressMessages(
mod.Phisex.psex <- crm(dipper.proc,dipper.ddl,model.parameters = list(Phi=list(formula=~sex),p=list(formula=~sex)),method="Nelder-Mead",hessian = TRUE)
),file="temp.txt")
mod.Phisex.psex##
## crm Model Summary
##
## Npar : 4
## -2lnL: 666.1518
## AIC : 674.1518
##
## Beta
## Estimate se lcl ucl
## Phi.(Intercept) 0.22338784 0.1440981 -0.0590445 0.5058202
## Phi.sexMale 0.04138178 0.2041878 -0.3588263 0.4415899
## p.(Intercept) 2.01072100 0.4210671 1.1854294 2.8360126
## p.sexMale 0.47587463 0.6630165 -0.8236377 1.7753870mod.Phisex.psex$results$AIC## [1] 674.1518# compare all models with AIC ----------------------------
# Set up models to run (must have either "Phi." or "p." in the name)
Phi.dot <- list(formula=~1)
Phi.time <- list(formula=~time)
Phi.sex <- list(formula=~sex)
Phi.timesex <- list(formula=~sex+time)
p.dot <- list(formula=~1)
p.time <- list(formula=~time)
p.sex <- list(formula=~sex)
p.timesex <- list(formula=~sex+time)
cml=create.model.list(c("Phi","p")) # create list of all models to run
# Run all models ----------------------------
capture.output(suppressMessages(suppressWarnings(
allmodels <- crm.wrapper(cml,data=dipper.proc, ddl=dipper.ddl,external=FALSE,accumulate=FALSE,method="Nelder-Mead",hessian=TRUE)
)),file="temp.txt")
# AIC model selection ----------------------------
allmodels## model npar AIC DeltaAIC weight neg2lnl
## 1 Phi(~1)p(~1) 2 670.8377 0.000000 0.3792707172 666.8377
## 2 Phi(~1)p(~sex) 3 672.1934 1.355756 0.1925531715 666.1934
## 5 Phi(~sex)p(~1) 3 672.6762 1.838541 0.1512568696 666.6762
## 9 Phi(~time)p(~1) 7 673.7301 2.892463 0.0893015564 659.7301
## 6 Phi(~sex)p(~sex) 4 674.1518 3.314151 0.0723253541 666.1518
## 10 Phi(~time)p(~sex) 8 675.1913 4.353613 0.0430104833 659.1913
## 13 Phi(~sex + time)p(~1) 8 675.6617 4.824056 0.0339952989 659.6617
## 14 Phi(~sex + time)p(~sex) 9 677.1681 6.330419 0.0160072363 659.1681
## 3 Phi(~1)p(~time) 7 678.4804 7.642778 0.0083050299 664.4804
## 4 Phi(~1)p(~sex + time) 8 679.9497 9.112045 0.0039837661 663.9497
## 7 Phi(~sex)p(~time) 8 680.4921 9.654404 0.0030375415 664.4921
## 11 Phi(~time)p(~time) 12 681.0644 10.226756 0.0022815888 657.0644
## 12 Phi(~time)p(~sex + time) 13 681.7032 10.865580 0.0016577483 655.7032
## 8 Phi(~sex)p(~sex + time) 9 681.8896 11.051978 0.0015102292 663.8896
## 15 Phi(~sex + time)p(~time) 13 682.9670 12.129303 0.0008812611 656.9670
## 16 Phi(~sex + time)p(~sex + time) 14 683.6633 12.825655 0.0006221479 655.6633
## convergence
## 1 0
## 2 0
## 5 0
## 9 0
## 6 0
## 10 0
## 13 0
## 14 0
## 3 0
## 4 0
## 7 0
## 11 0
## 12 0
## 8 0
## 15 0
## 16 1# get parameter estimates and confidence intervals for best model
allmodels[[1]]##
## crm Model Summary
##
## Npar : 2
## -2lnL: 666.8377
## AIC : 670.8377
##
## Beta
## Estimate se lcl ucl
## Phi.(Intercept) 0.2422903 0.1020150 0.04234102 0.4422397
## p.(Intercept) 2.2261889 0.3251153 1.58896300 2.8634148allmodels[[11]]##
## crm Model Summary
##
## Npar : 12
## -2lnL: 657.0644
## AIC : 681.0644
##
## Beta
## Estimate se lcl ucl
## Phi.(Intercept) 0.75646636 0.6570806 -0.5314115 2.0443443
## Phi.time2 -0.99255899 0.7541098 -2.4706141 0.4854961
## Phi.time3 -0.84151202 0.6991671 -2.2118796 0.5288556
## Phi.time4 -0.22522075 0.7051952 -1.6074033 1.1569618
## Phi.time5 -0.36893542 0.6974964 -1.7360283 0.9981575
## Phi.time6 0.10115137 1.5063612 -2.8513166 3.0536194
## p.(Intercept) 1.00571207 0.8006507 -0.5635632 2.5749874
## p.time3 1.49463757 1.3119502 -1.0767848 4.0660600
## p.time4 1.37853596 1.0927335 -0.7632218 3.5202937
## p.time5 1.12053506 0.9914942 -0.8227935 3.0638636
## p.time6 1.57229762 1.0715539 -0.5279481 3.6725434
## p.time7 0.07823848 1.7821196 -3.4147158 3.5711928# make predictions and plot them.
predict(allmodels[[1]])$Phi## occ estimate se lcl ucl
## 1 6 0.560278 0.02513307 0.5105837 0.6087926Phi_by_year <- predict(allmodels[[11]])$Phi # predict Phi for all years (based on the best Phi(t) model)
suppressWarnings( suppressMessages( library(Hmisc,quietly = T) )) #load Hmisc package- has a nice error bar function
plot(1:nrow(Phi_by_year),Phi_by_year$estimate,xlab="Year",ylab="Survival",ylim=c(0,1),main="Variability in Survival, dipper demo")
errbar(1:nrow(Phi_by_year),Phi_by_year$estimate,Phi_by_year$ucl,Phi_by_year$lcl,add=T)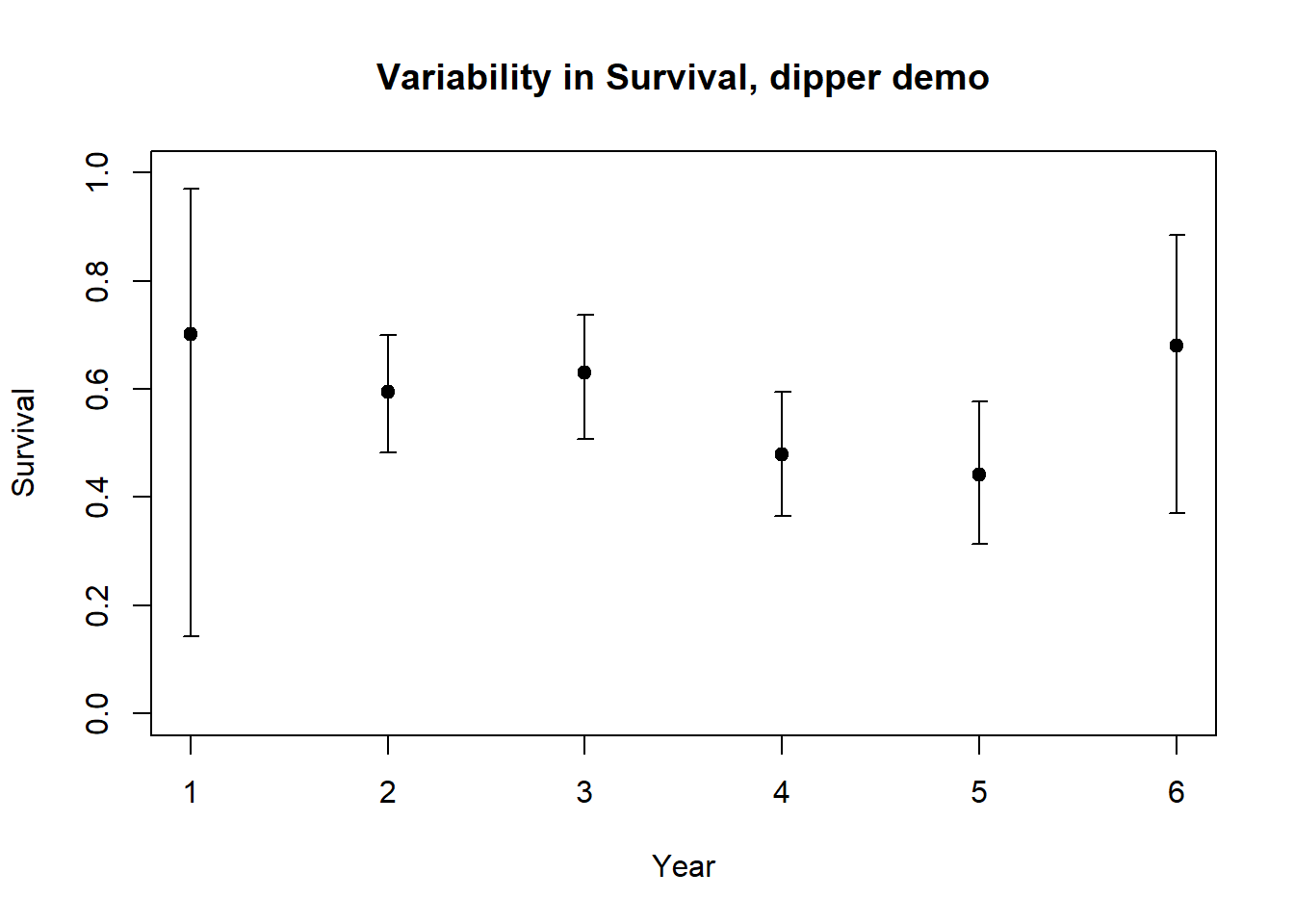
What is our estimate for mean survival?
# Compute the mean survival rate for the population -----------------------
mean(Phi_by_year$estimate)## [1] 0.5880352What is the environmental stochasticity?
# Compute the environmental variablility in annual survival rates ----------------
sd(Phi_by_year$estimate)## [1] 0.1066587Extras
Maximum likelihood: a framework for statistical inference!
FOR CMR ANALYSIS: - What value of survival maximizes the probability of generating the observed capture histories?
EXAMPLE:
Consider the following capture history for a single individual:
1 0 1 1This individual was marked and released upon initial capture. It was not captured in the next survey, but then was captured in each of the next two subsequent surveys.
What is the probability of observing this capture history?
[(Probability of surviving from time 1 to 2) X (Probability of not being seen at time 2)] X [(Probability of surviving from time 2 to 3) X (Probability of being seen at time 3)] X [(Probability of surviving from time 3 to 4) X (Probability of being seen at time 4)]
This can be written:
\(L_1 = \phi_1(1-p_2) \cdot \phi_2p_3 \cdot \phi_3p_4\)
How about the following capture history for a single individual:
1 0 1 0What is the probability of observing this capture history?
[(Probability of surviving from time 1 to 2) X (Probability of not being seen at time 2)] X [(Probability of surviving from time 2 to 3) X (Probability of being seen at time 3)] X
– either –
[(Probability of surviving from time 3 to 4) X (Probability of not being seen at time 4)]
– or –
[(Probability of NOT surviving from time 3 to 4)
This can be written:
\(L_1 = \phi_1(1-p_2) \cdot \phi_2p_3 \cdot \left \{(1-\phi_3)+\phi_3(1-p_4) \right \}\)
Q: if survival were 100% and capture probability were 100%, what is the probability of observing the above capture histories?
Q: what about if survival was 100% and capture probability was 75%?
Maximum likelihood estimation is the process of finding those values of the parameters \(\phi\) and \(p\) that would be most likely to generate the observed capture histories!
This model is known as the Cormack-Jolly-Seber model (CJS), and is the most common analysis performed by Program MARK.
Q: Why is \(\phi\) also known as “apparent” survival? Why is it not “true” survival???